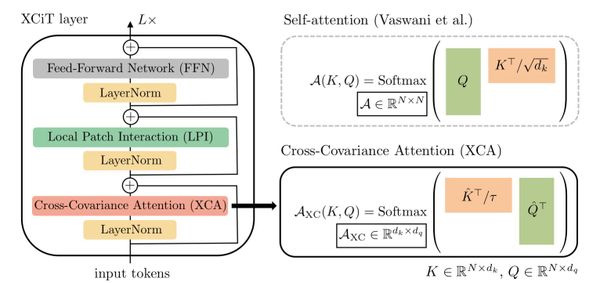
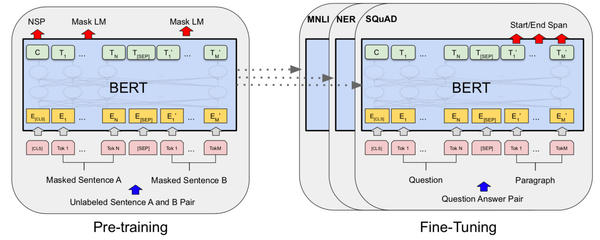
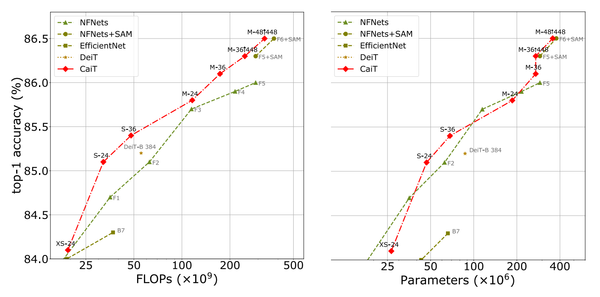
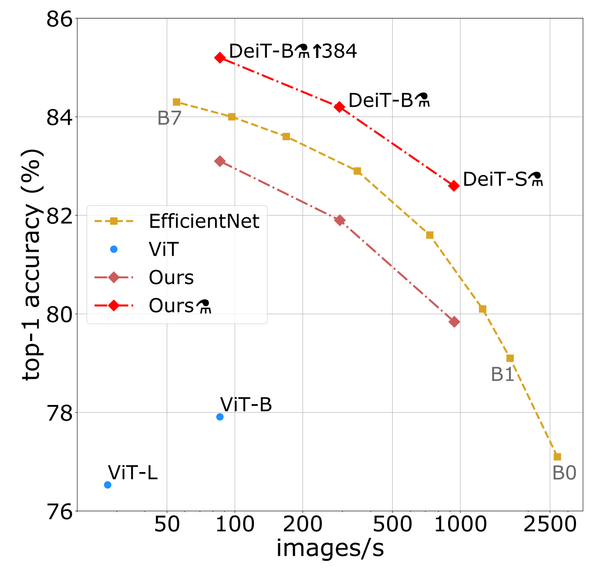
Segment Anything (SAM) proposes a flexible foundation model for image segmentation. It can respond to query points, boxes, masks, or text, and return masks corresponding to those prompts. Curcially, this design allows for zero or few-shot transfer learning to a wide variety of tasks.