FixMatch, FlexMatch, and Semi-Supervised Learning (SSL)
In today's post I cover semi-supervised learning (SSL), specifically in the context of the FixMatch and FlexMatch algorithms.


Semi-supervised learning (SSL) is a model training regimen that leverages unlabeled samples to augment small amounts of labeled data with the goal of improving classification performance for datasets with sparsely labeled samples. FlexMatch, from Zhang et al.[1], is a recently released SSL method that tops state-of-the-art (SOTA) results on a variety of SSL benchmarks on datasets such as CIFAR-100 and STL-10. Here I'll give a brief intro to SSL, followed by a discussion of the FixMatch[2] and FlexMatch algorithms.
Semi-supervised learning (SSL)
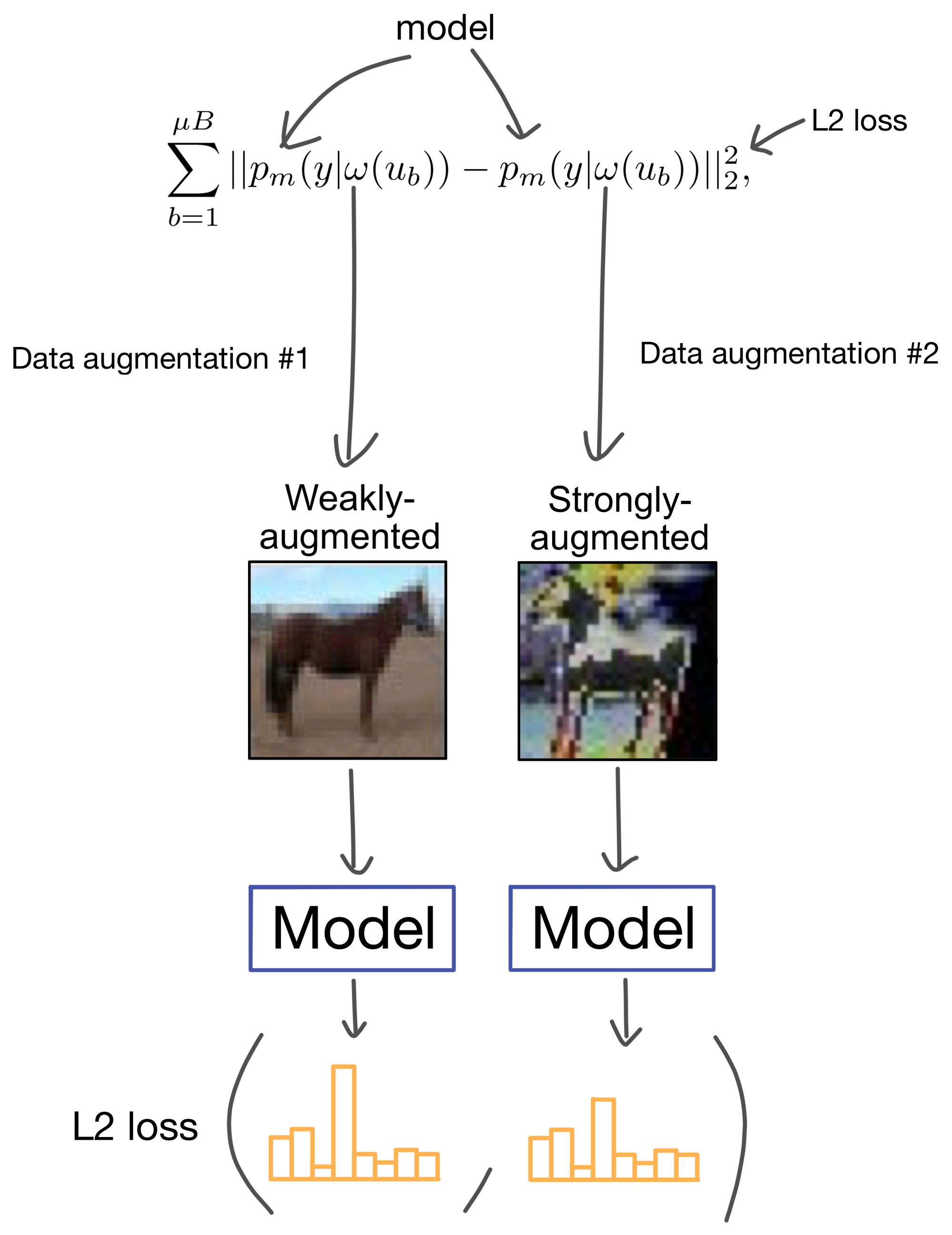
Briefly, SSL refers to the use of unlabeled data in conjunction with labeled data to boost model performance. SSL has many formulations, but one such flavor is a method known as pseudo-labeling. With pseudo-labeling, artificial labels are produced for unlabeled images, and the model is then asked to predict the artificial label during training. Another common SSL method is consistency regularization , where an artificial label is obtained using the models own predicted probability distribution after stochastic data augmentations to the input image. FixMatch[2] and FlexMatch use a combination of these two approaches (don't worry if those descriptions make total sense yet, they're discussed in more detail later in the post).
FlexMatch is essentially the FixMatch with a few twists, so I'll cover the FixMatch algorithm first.
FixMatch
FixMatch uses both consistency regularization and pseudo-labeling to generate artificial labels during SSL. Specifically, for unlabeled images FixMatch applies weak and strong augmentation to the same image, and then takes the cross entropy of the class prediction probability distribution for the two images.
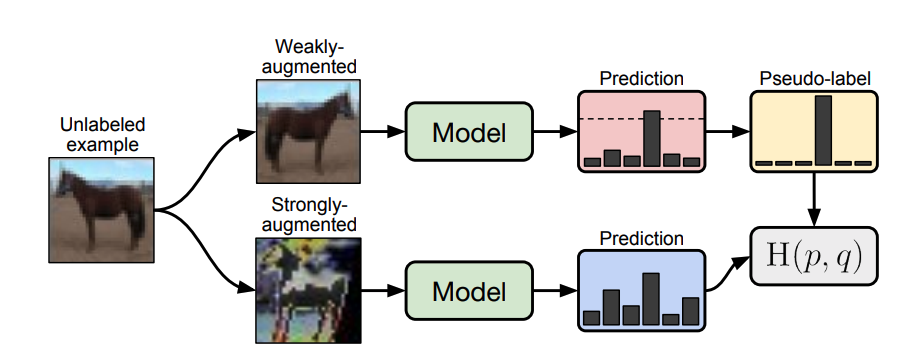
That's really just about it, the method is actually quite simple. There is however one wrinkle: the prediction is added to the loss only IF the maximum class probability for the weakly-augmented image is greater than some threshold T.
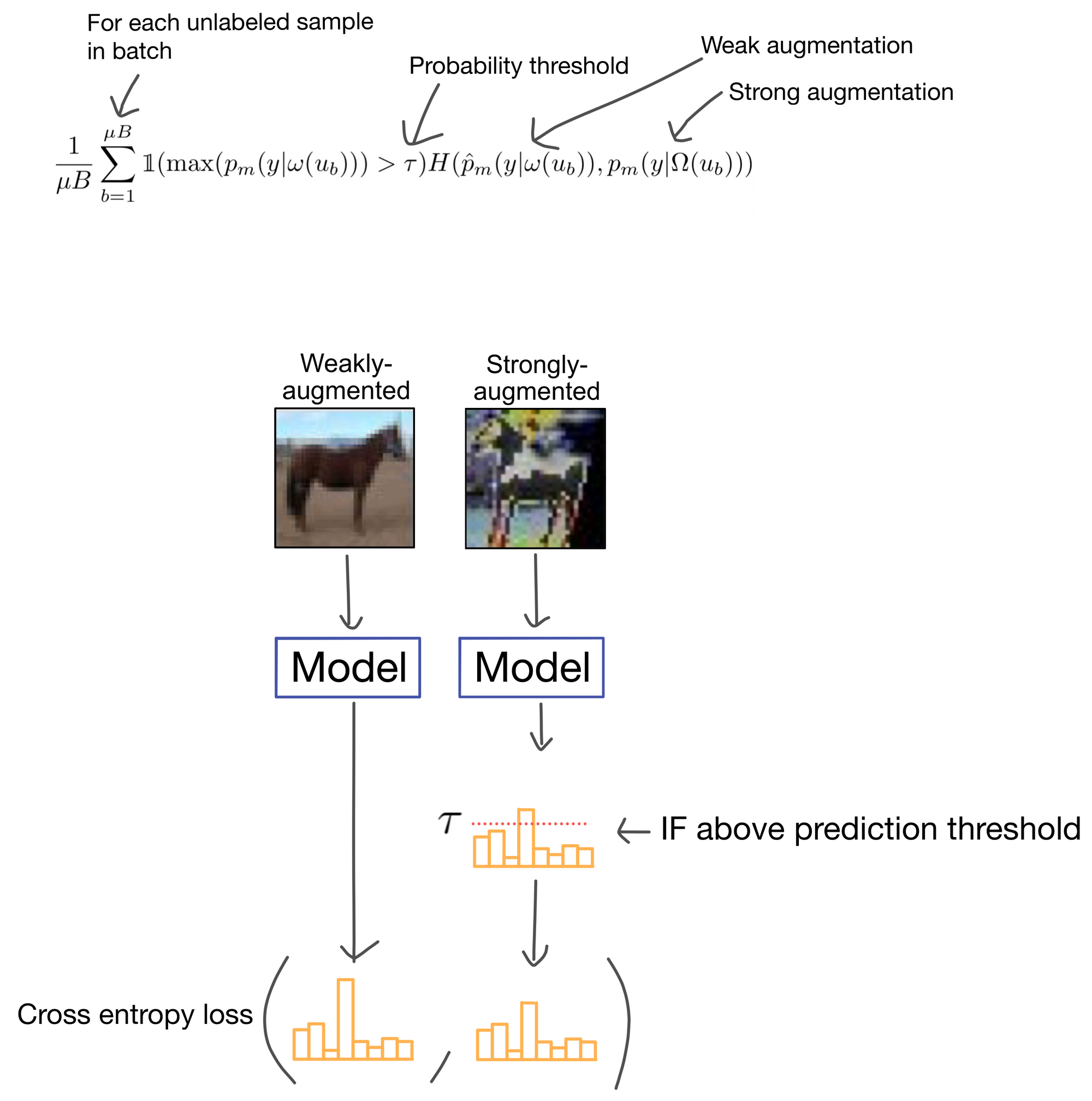
FlexMatch
FlexMatch utilizes FixMatch as a starting point, however they make one modification that results in a >10% accuracy gain on several SSL benchmarks: they make the probability threshold T adjustable for each class, rather than a fixed hyperparameter. This adjustment allows the method to account for differences in classification difficulty between classes, which is an issue with FixMatch's static probability threshold. They term this method of labeling Curriculum Pseudo Labeling (CPA).

The formulas used for adjusting T are shown above. Without enumerating too many of the details here, the general idea is that the probability threshold is adjusted to be higher for classes that are easier to predict, and lower for classes that are more difficult to predict. In doing this, the model gains more exposure to harder classes that it wouldn't otherwise learn with a fixed probability threshold.
A warmup period
The authors found T to be unstable at early stages of training and sensitive to initialization of model parameters, so they introduce a new denominator to the learning effect formula (which is used to scale T). To decrease swings during early training steps the scaling denominator is set to the max of the learning effect for all classes and the number of unused samples. The change ultimately has the effect gradually raising T through the early stages of learning.

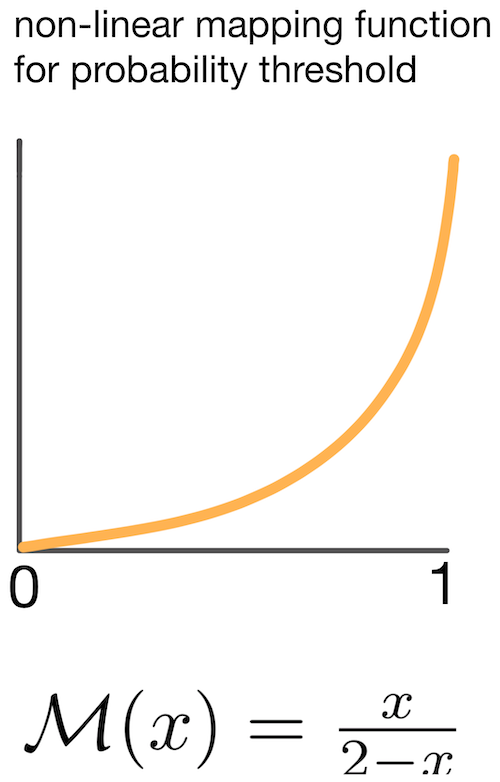
A non-linear mapping function for T
One final note to mention is that FlexMatch uses a non-linear mapping function for T. This lets the threshold grow slowly when the learning effect is small, and more quickly when the learning effect grows; a modification they empirically show improves learning.
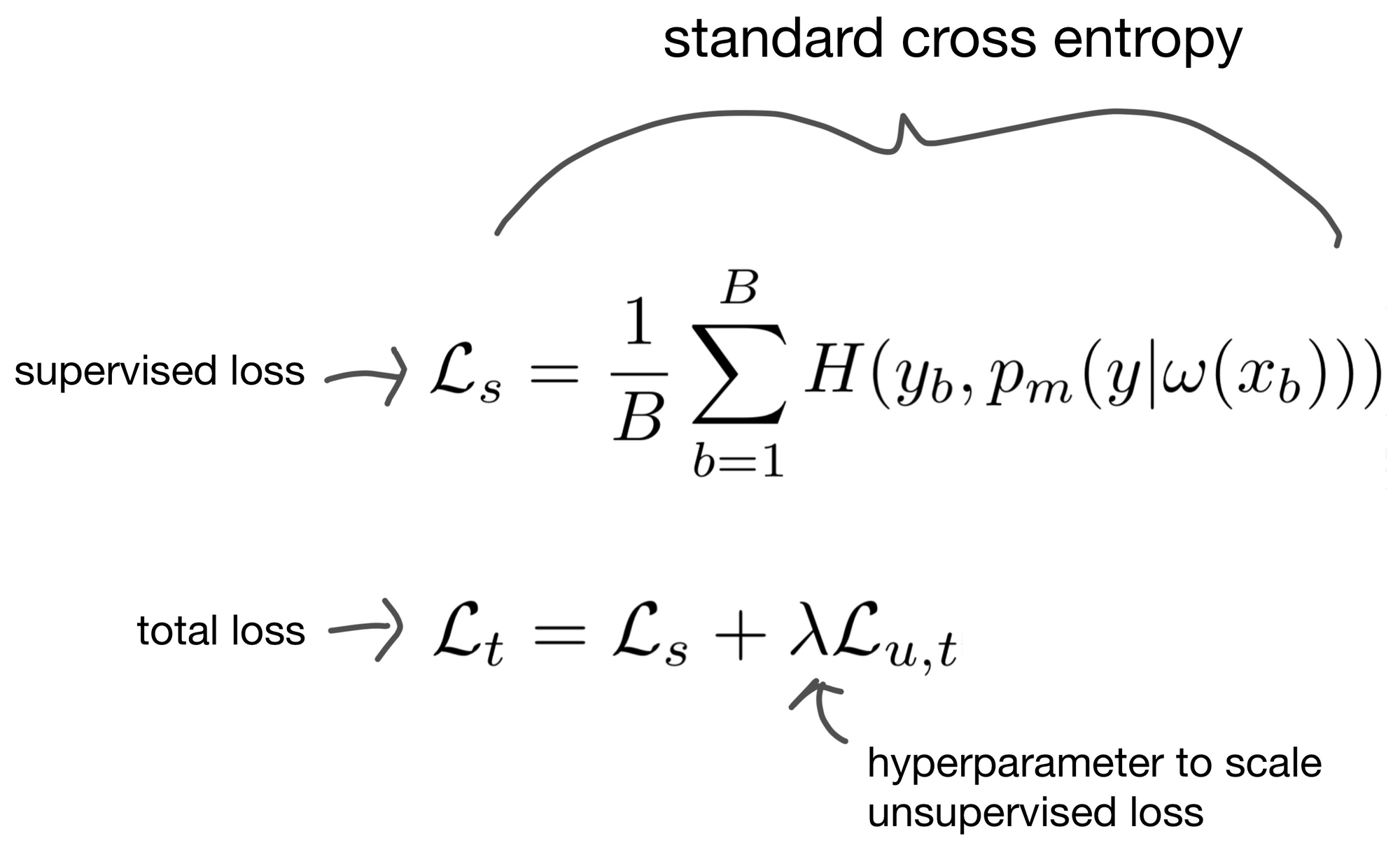
The final loss function
Above we described the unsupervised loss, what about the supervised loss for images that we actually have real labels for? For these images we simply calculate cross entropy the same way we would in a typical supervised classification problem. The two losses, supervised and unsupervised, are then summed to produce the final loss term. Additionally, there is an added hyperparameter to scale the unsupervised loss, allowing for adjustment of how much impact the unsupervised loss has on model training.
Hope you enjoyed the post :)
1. FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling, https://arxiv.org/abs/2110.08263
2. Simplifying Semi-Supervised Learning with Consistency and Confidence: https://arxiv.org/abs/2001.07685