Paper Walkthrough: CaiT (Class-Attention in Image Transformers)
In this post, I cover the paper Going deeper with image transformers by Touvron et al, which introduces LayerScale and Class-Attention Layers.

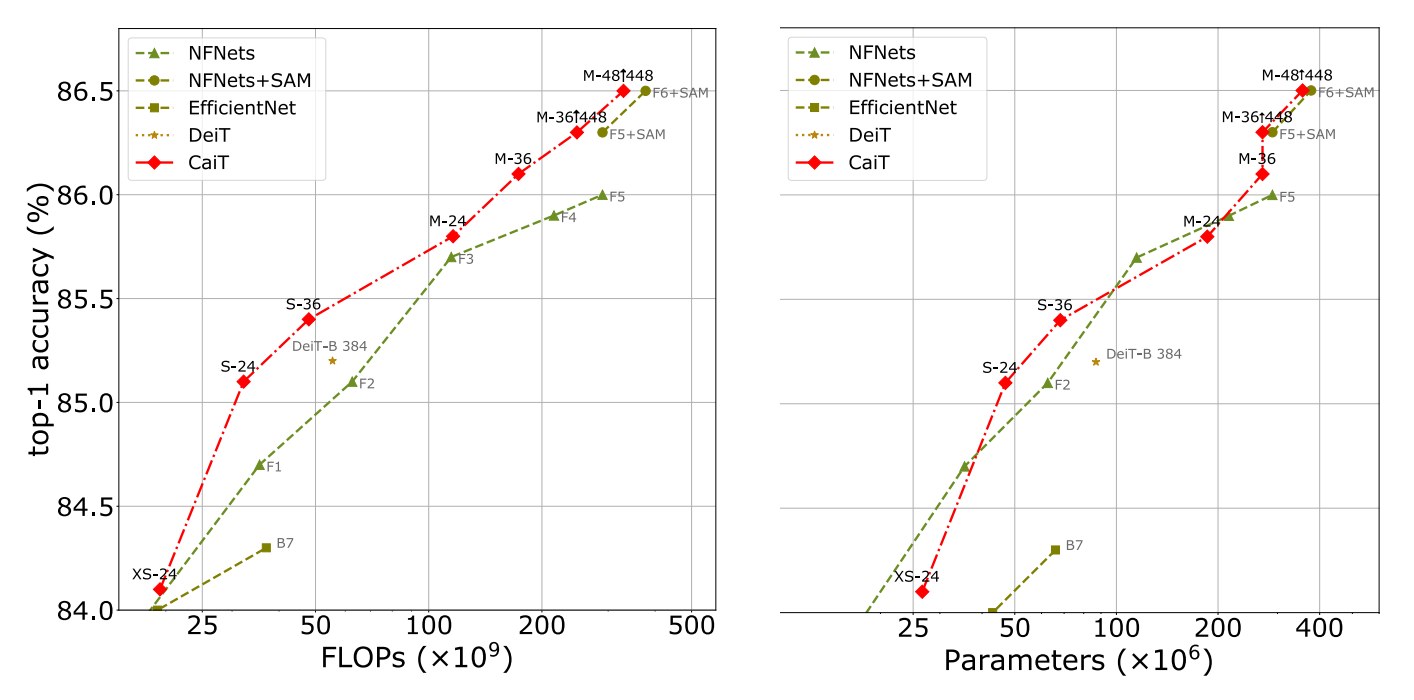
In the past year transformers have become suitable to computer vision tasks, particularly for larger datasets. In this post I'll cover the paper Going deeper with image transformers by Touvron et al. In which they extend ViT [2] (also see previous ViT post here) and achieve SOTA performance (at the time of writing) for ImageNet classification.
Takeaways
- Top-1 accuracy on ImageNet. Additionally while doing so CaiT uses less total network parameters and has higher image throughput.
- The introduction of LayerScale, a step applied to the output of each feed forward or self-attention block that allows learned parameters to control how much weight is given to the residuals vs. the output of the block.
- Additionally, the paper proposes the concept of class-attention layers, which separate the transformers layers responsible for spreading information between images patches, and those routing information from the image patches to the class token. This concept allows for the model to learn to optimize for each of these tasks separately, avoiding contradictory signals towards the learning objective.
- These new concepts also translate to performance gains for transfer learning tasks.
Walkthrough
LayerScale
LayerScale is #1 of the 2 major paper contributions.
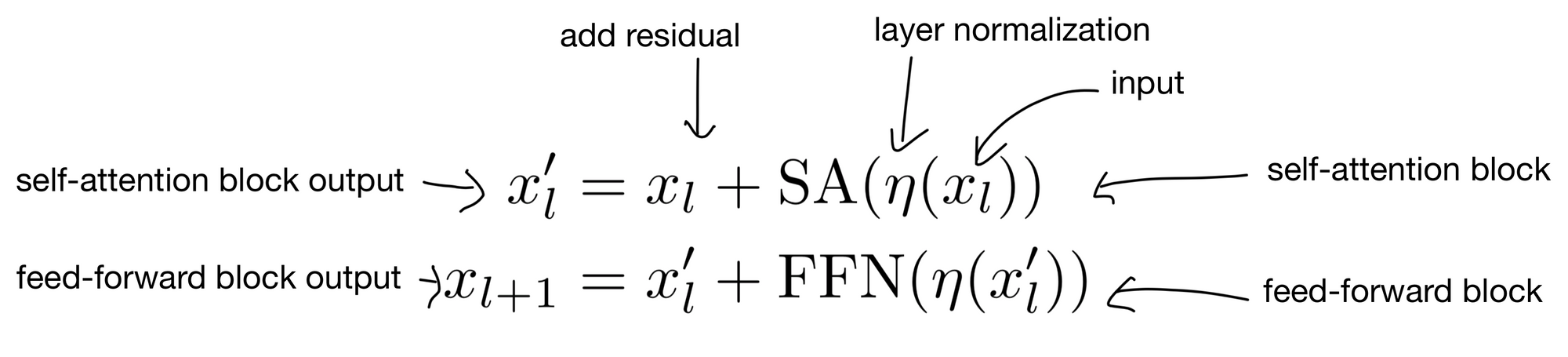
Above is the overall flow of the activations through a transformer encoder layer. LayerScale changes how the residual inputs are added to the output of the FFN and self-attention (SA) blocks.
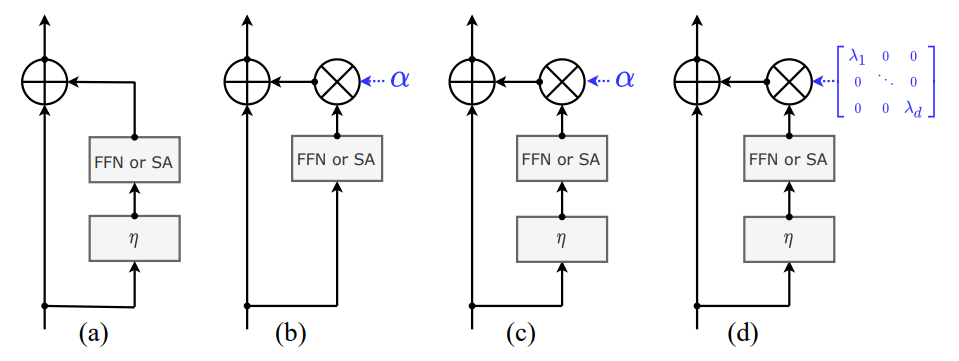
Here we see four ways of adding the input residual to the block output. In A the residuals are just simply added to the output of the block, as they are in base ViT [2]. In B we see how residuals have been added in previous methods ReZero/Skipinit and Fixup. Here LayerNorm is taken away before the SA and FNN block and a learnable parameter is added to scale how much of the SA/FFN block output is added to the residual. The authors of this paper actually found that this method worked better if LayerNorm is added back in, which is C. Finally, in D we see LayerScale. A learnable diagonal weight matrix is dotted with the block output. As we see below, by taking the dot product of the diagonal weight matrix and block output, we allow for each channel (dimension d) of the block output to be scaled separately, thus giving the network more control over how much signal gets through from each channel. There are two diagonal weight matrices in each layer (one for the FFN block and another for the SA block), and they are initialized with values close to zero.
Class-Attention Layers
Concept #2 is that of the Class-Attention Layer, which is targeted at addressing the issue of contradictory learning signals in ViT architectures. The two contradictory objectives are 1) mixing information between image patches, and 2) summarizing the information from image patches for the class token that is eventually used in the MLP classification head. Ultimately, this is detrimental to the network because one set of weights is learned for two different purposes.
Class-Attention Layers solve this issue by controlling A) when the class token is added into the stack of transformer layers, and B) not allowing the class token to transfer information to the patch embeddings after it is added to the encoder stack. The figure below from the paper shows the base ViT (right), the addition of the class token part-way through the encoder stack (middle), and the addition of class token after self-attention only layers and with class-attention layers
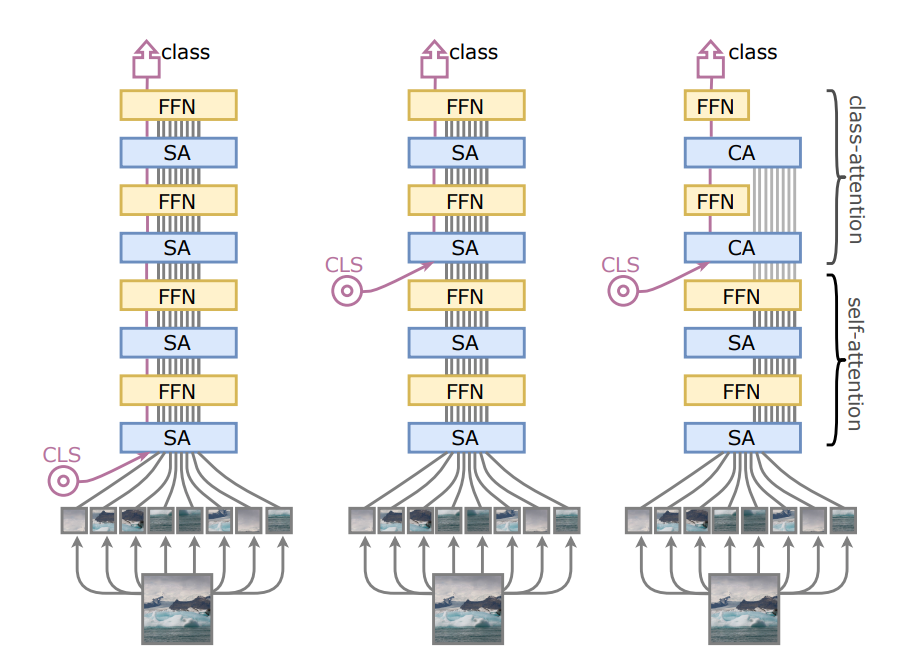
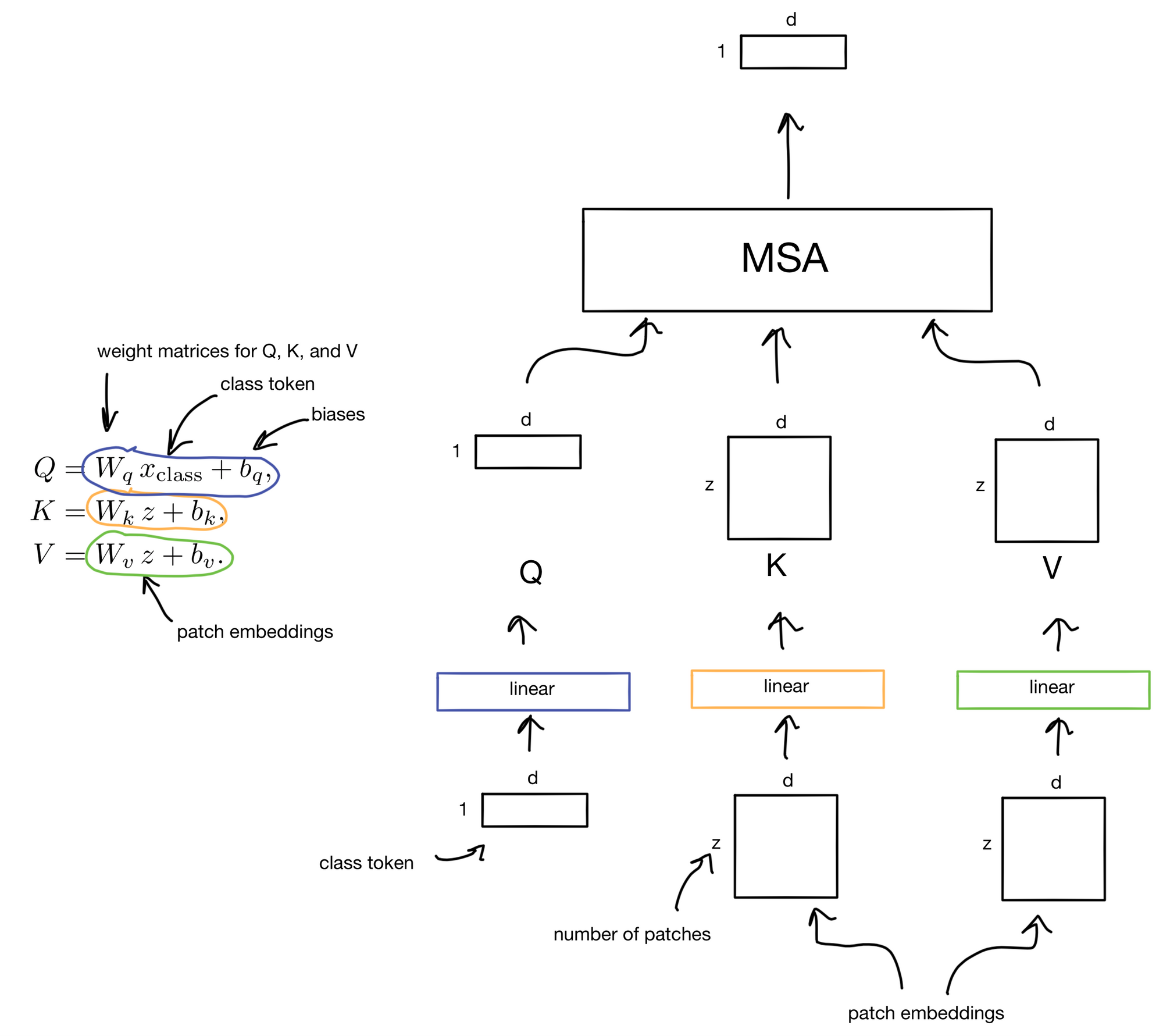
Below is a walkthrough of the tensor operations in the MSA head showing how the class token is only learning to attend to information in the patch embeddings, and not the other way around. The patch embeddings are also no longer projected through the FFN, effectively freezing them after the class token is added. This allows each encoder layer to focus solely on its respective task; learning the self-attention between image patches, or transferring information to the class token.
Hope you found the post useful. Cheers :)
1. CaiT: https://arxiv.org/abs/2103.17239
2. ViT: https://arxiv.org/abs/2010.11929