Paper Walkthrough: Bidirectional Encoder Representations from Transformers (BERT)
This week, I cover Bidirectional Encoder Representations from Transformers (BERT).

BERT [1] from Delvin et al. is a model designed for natural language processing (NLP) tasks that, in my mind, was probably the second biggest breakthrough in transformer architectures for NLP. Behind only the Transformer from Vaswani et al. introducing the transformer architecture [2], which used an encoder with multi-head self-attention (MSA) that is still used in many transformer architectures today.
So what made BERT so transformational? It introduced a self-supervised (no labeled training data) pre-training scheme that allowed for the learning of bidirectional representations of input sequences (more on that later). This pre-training regimen ultimately allowed improvement in various transfer learning benchmarks, achieving SOTA results in many of them. Since the pre-trained BERT model is so useful for a variety of tasks, pre-trained models can be trained on massive datasets by organizations (such as huggingface) with access to large pools of computing resources. The resulting models can be easily fine-tuned by end users with access to orders of magnitude less compute for downstream, domain specific tasks.
BERT
Bidirectional representations
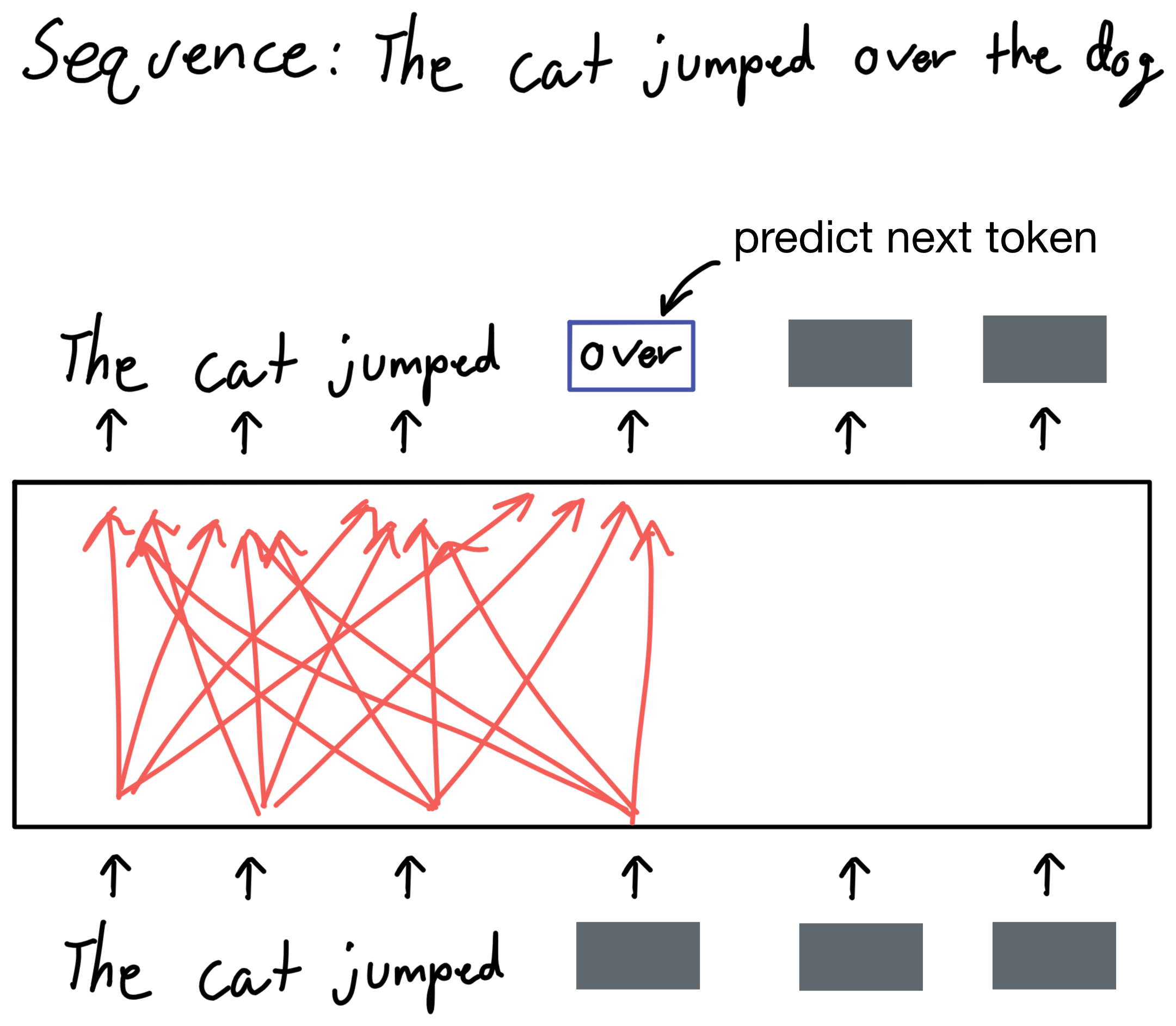
Before BERT, many architectures, such as the first version of GPT [3] used a pre-training objective where the goal was to predict the next token in a sentence. Due to the nature of the task itself, the model can't "look ahead" in the input sentence because that would give away the answer to the task the model is trying to accomplish. For this reason, the model only has access to words in the input sequence before the token being predicted. Or in other words, the model can only learn unidirectional representations from the input sequences.
Take for example the sentence the cat jumped over the dog. If the model is given the tokens the cat jumped and we except the model to predict the next token, over, it will only have access to information in the tokens the cat jumped, but not the tokens the dog. This is vital context that is important to NLP tasks.
Quick side note - typically input sequences are tokenized for NLP tasks. For example, the verb jumped would be split into two tokens, <jump> and <ed>. Additionally rarer tokens, such as proper knowns, are usually represented by a single token to limit vocabulary size. However, for simplicity sake I ignore tokenization for this post. Also ignore the (poorly) handwritten text in the explanatory figures.
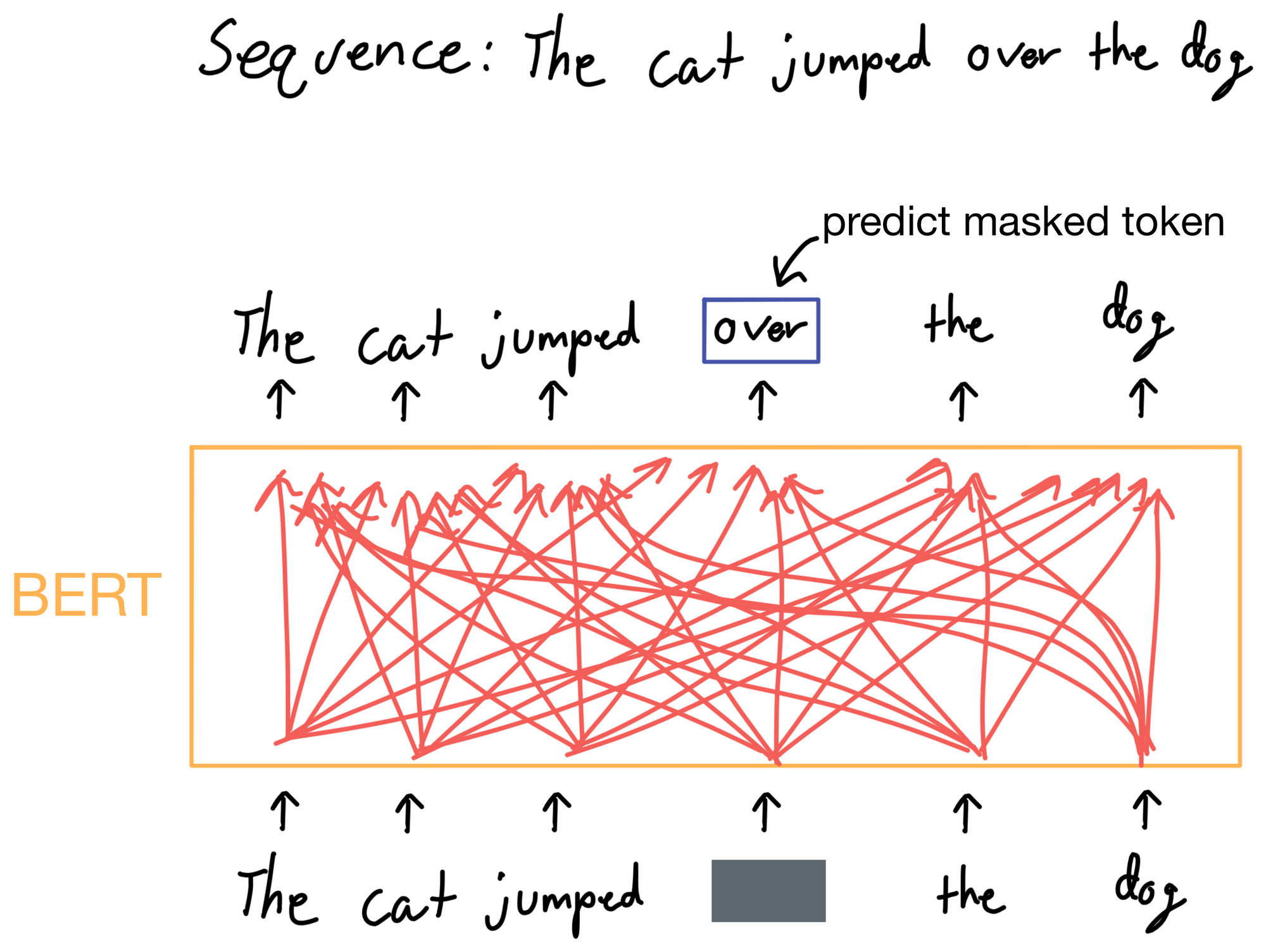
BERT solves this issue by slightly modifying the training task to allow the model to learn bidirectional representations. Instead of simply predicting what token comes next in a sequence, BERT masks random tokens in the input sequence and asks the model to predict what the masked token is. As a result, the model now has access to tokens in the input sequence that occur not only before, but after the masked tokens, allowing it to gather information from all tokens in the sequence.
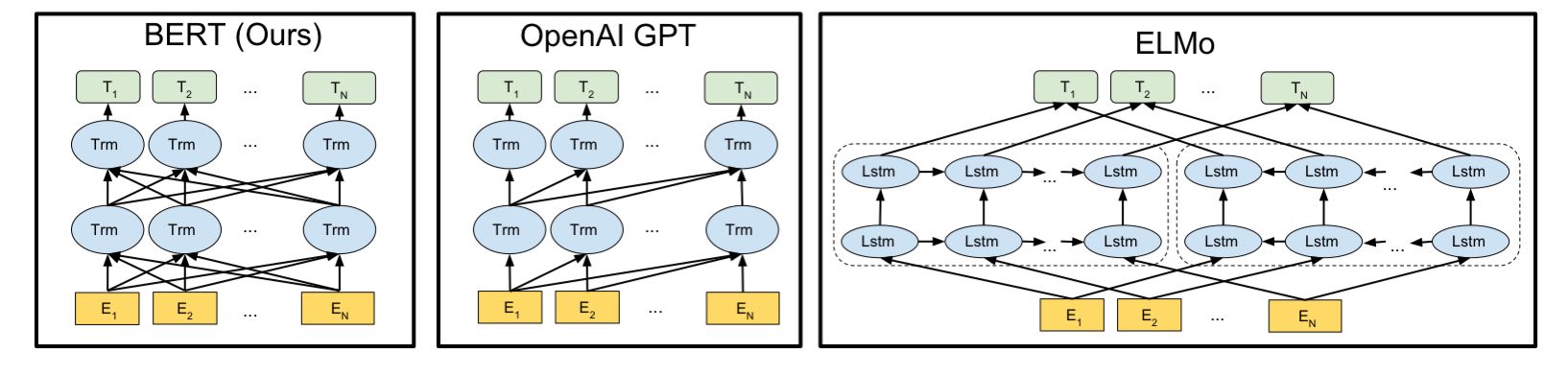
Below is a figure from the paper comparing BERT against GPT and ELMo[4]. I didn't explicitly mention ELMo above, but it is similar to GPT in that it auto-regressively predicts the next token in a sequence, except that there are two transformer encoders. One that "reads" left to right, and another from right to left. They are then combined to predict the desired token in the sequence. However, this architecture is still deficient in that it doesn't allow for the attention mechanism to mix information in the same encoder layer, as the left-right and right-left learning is happening in two separate encoders.
The <CLS> token
Token masking isn't the only change BERT implements in the self-supervised training objective. It also incorporates a binary classification task to predict whether two sequences are paired (i.e. next to each other in some input dataset). BERT incorporates this objective by inputing two input sentences, separated by a special <SEP> token, and predicts whether the sentences are paired or not. The actual prediction is made of a special <CLS> token that is concatenated to the front of the input tokens. This <CLS> token aggregates information via attention from all tokes in the input sequence, and is linearly projected for classification. This is an exceptionally powerful concept, and is a significant component of what allows BERT to fine-tune so well.
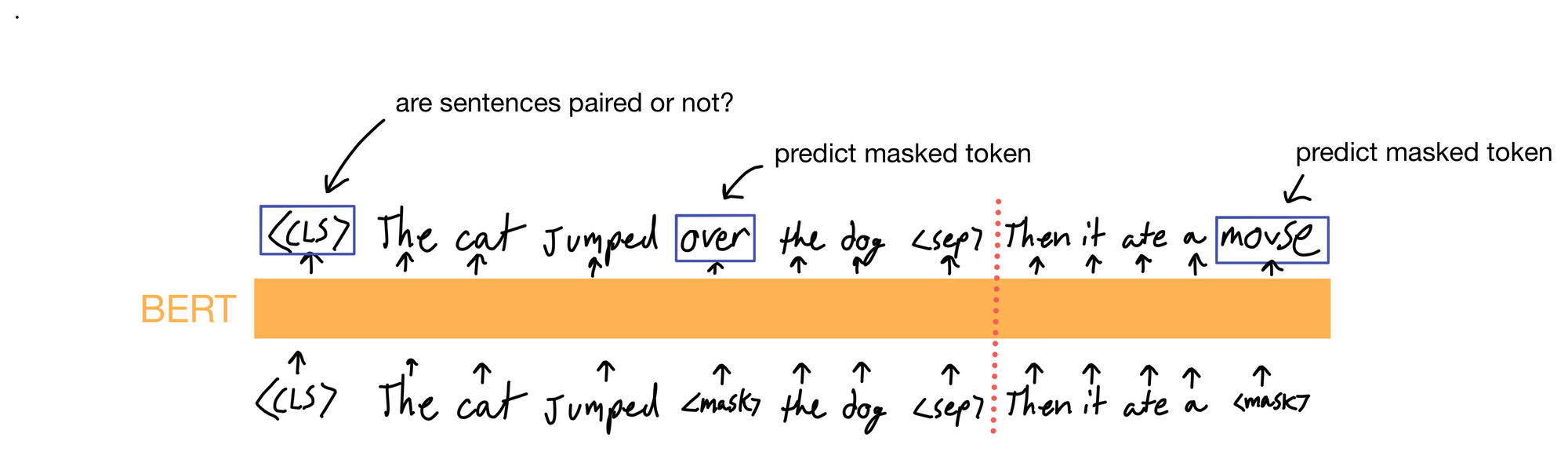
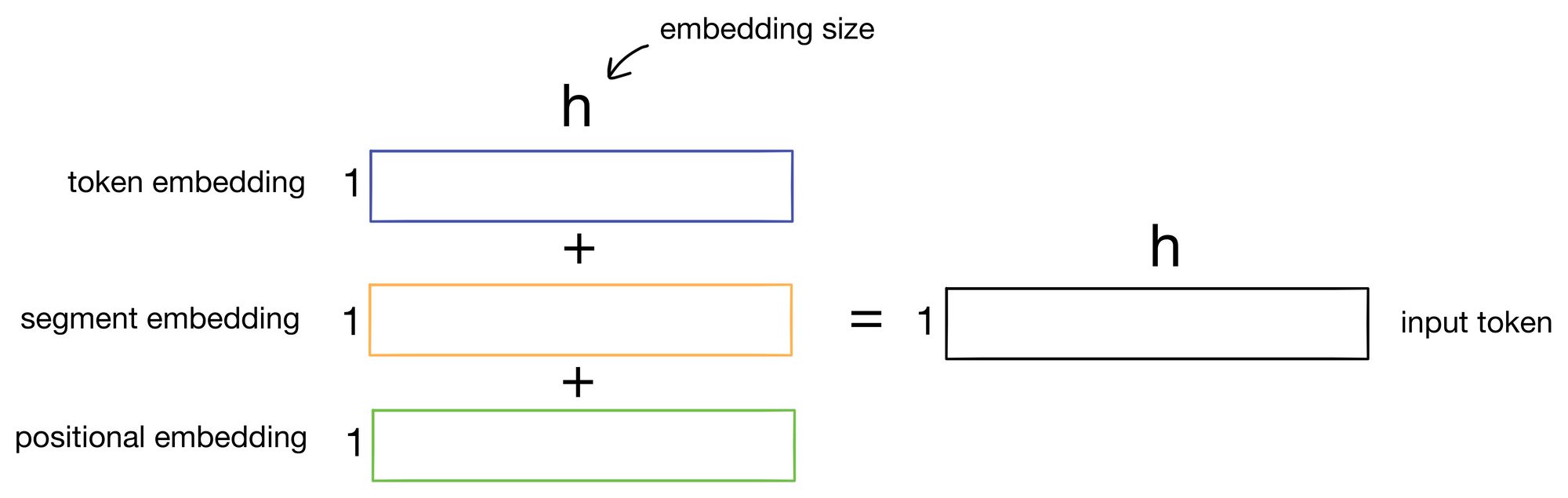
Finally, BERT also makes some changes to input token construction. It is common practice when training transformers to add a word embedding to a positional embedding to give the transformer context for where the token is in the input sequence. This is also done in BERT, except an additional segment embedding is also added. The segment embedding can take one of two possibilities and informs the model whether the token is part of the first or second sentence (i.e. before or after the <SEP> token) in the overall input sequence.
Transfer learning
The motivation behind the pre-training regimen is that it trains a model that is ideal for transfer to downstream tasks. The bulk of this power comes from the addition of the <CLS> token during pre-training, and token masking that forces the model to be context aware of tokens both before and after the masked token. These two components are useful in just about every NLP task, and explains why BERT is so adaptable.
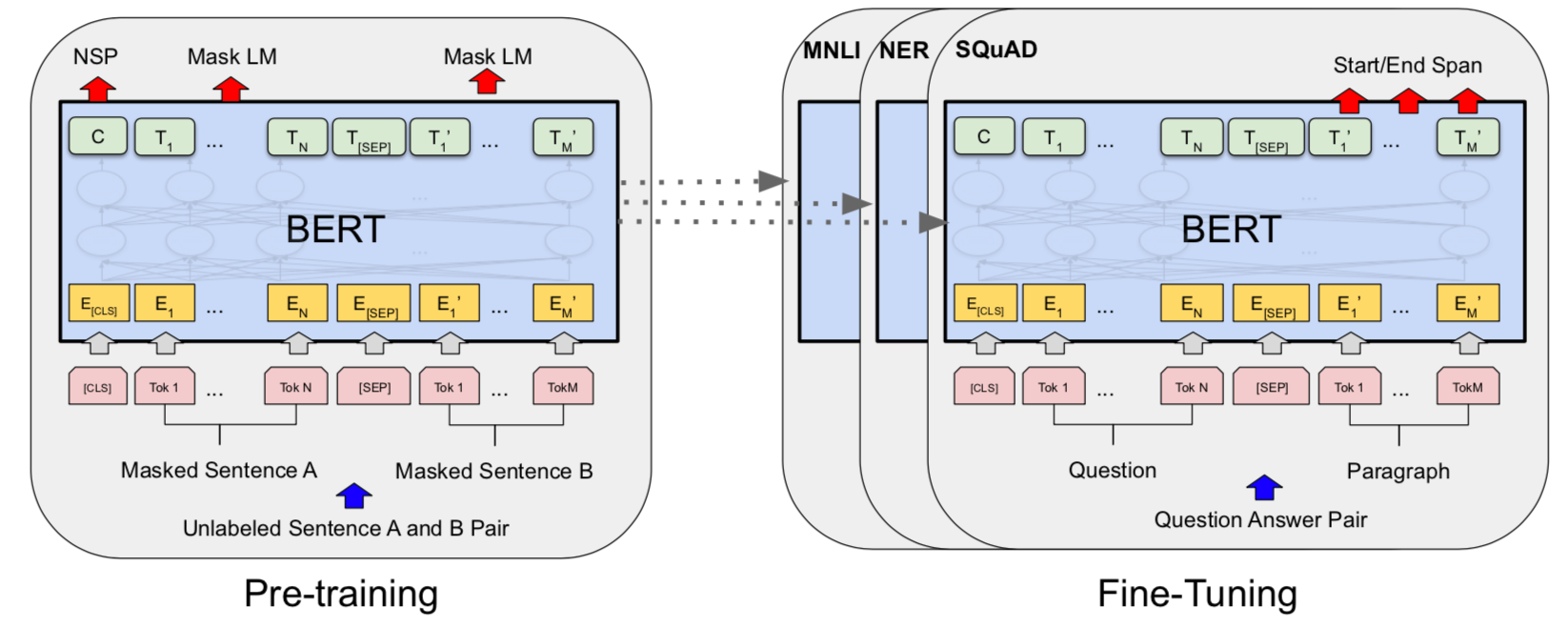
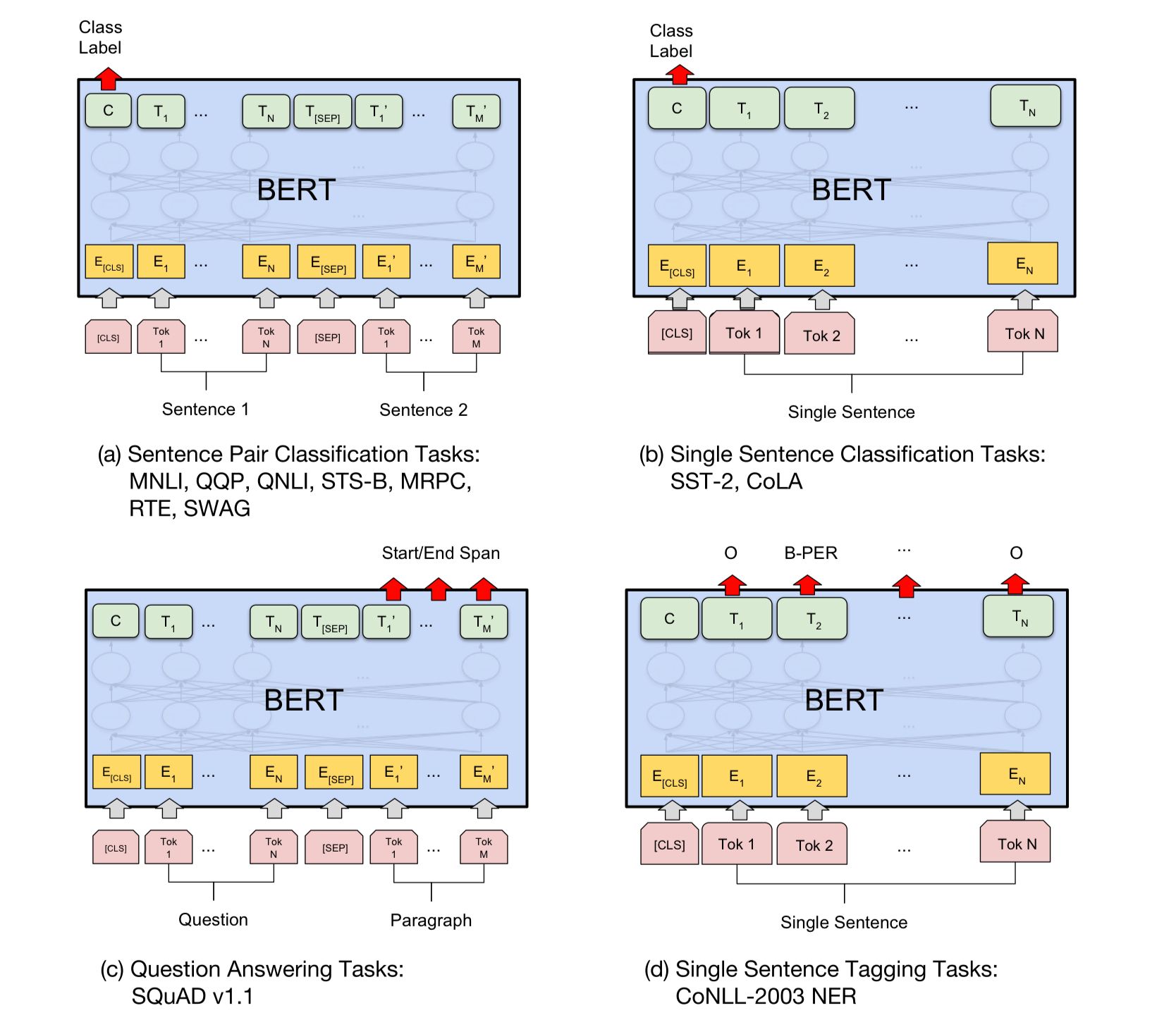
For each downstream task, task-specific inputs/outputs are applied to BERT. For example, in tasks such as sentiment analysis, the <CLS> token is used to classify the sentiment of an input sequence. Likewise, for tasks like sequence tagging, the token representations output by the encoder are used to classify a token as a particular tag. A visualization of some of these tasks is elegantly shown in the figure below from the paper.
Hope you enjoyed this weeks post :)
1. BERT: https://arxiv.org/abs/1810.04805
2. Transformer: https://arxiv.org/abs/1706.03762
3. GPT: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
4. ELMo: https://arxiv.org/abs/1802.05365