Explained: Multi-head Attention (Part 2)
Part 2 of 2 of an explanation of multi-head attention.


In this post I continue my description of scaled dot product attention from last week.
We left off with a (hopefully) well explained and motivated description of scaled dot product attention.
This attention operation is the backbone of the Transformer architecture, however there is a small wrinkle we need to address: multi-head attention.
Multi-head Attention
So, multi-head attention, what's it all about?
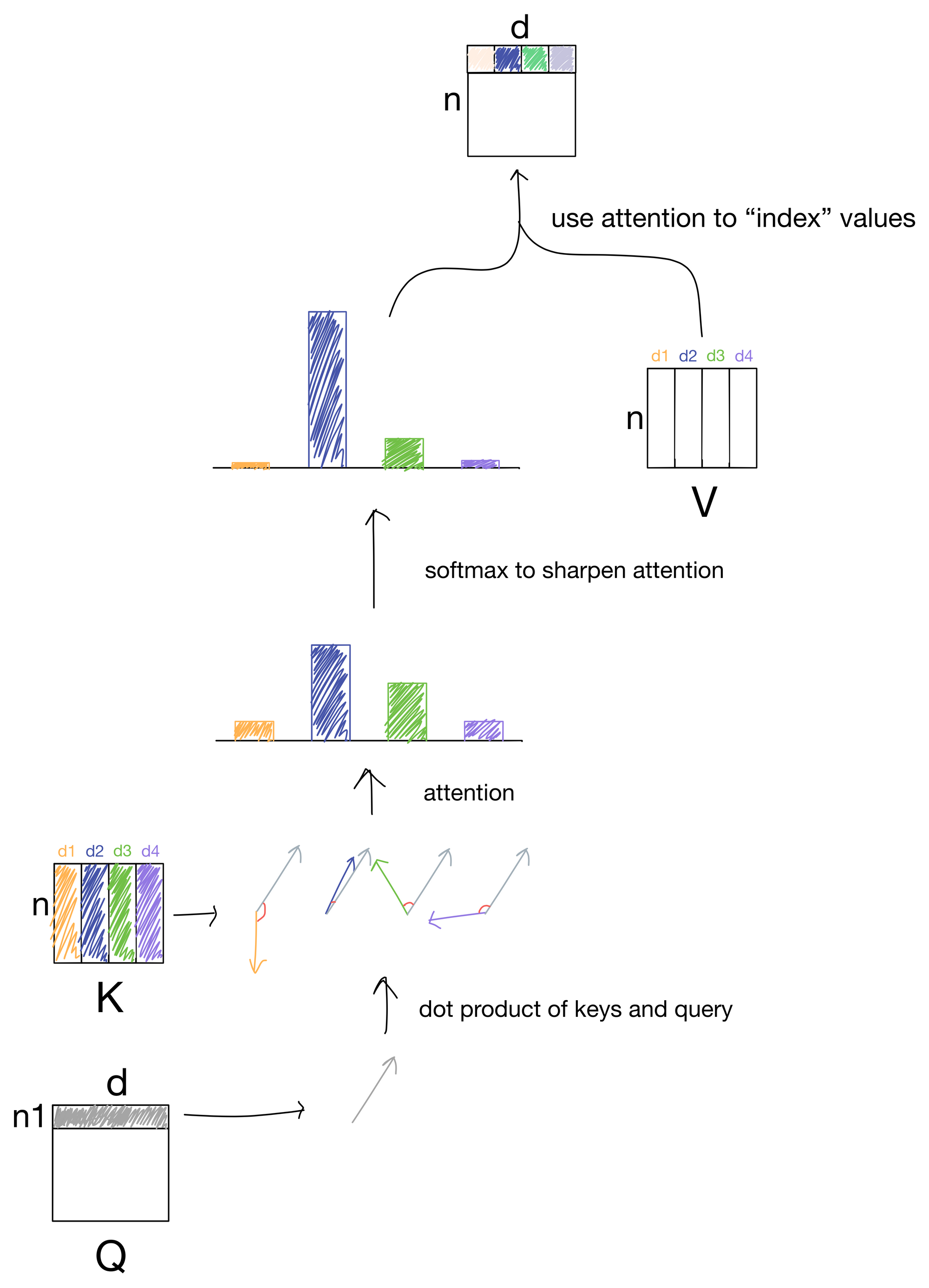
Multi-head attention allows for the network to learn multiple ways to "index" the value matrix V. In vanilla attention (without multiple heads) the network only learns one way to route information. In theory this allows for the network to learn a richer final representation of the input data.
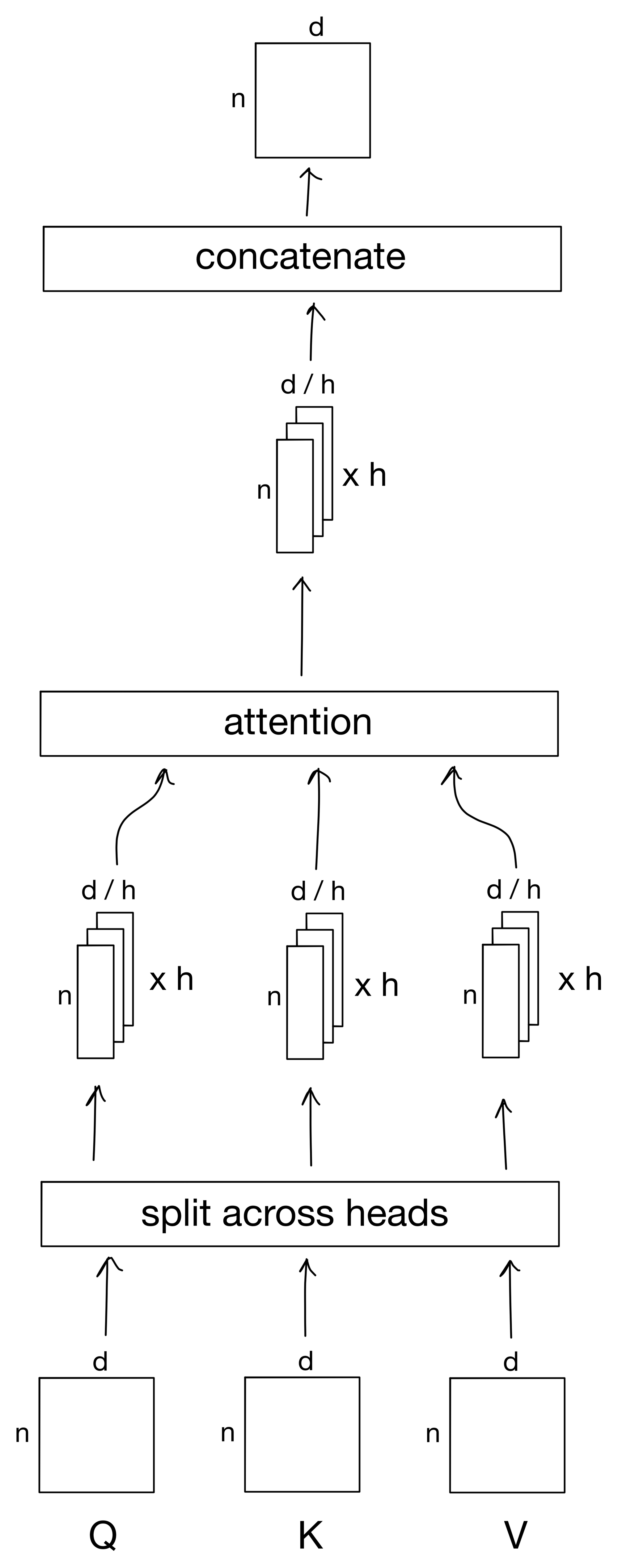
quite simple. To start, the keys, queries, and values input matrices are simply broken up by feature into different heads, each of which are responsible for learning a different representation. After each of these heads is passed through the attention mechanism (they are all treated the exact same way, the dimension of the matrices is just smaller). And at the end each head is concatenated back together to form the output n x d matrix.
The Transformer
Here I'll cover how multi-head attention is actually implemented in the Transformer architecture. For a more detailed (and also messy, it was my first post, forgive me :)) look at the Transformer architecture from Vaswani et al.[1] see my post here.
In their most basic form, models implementing the transformer architecture are typically composed entirely of an encoder or encoder + decoder followed by a task-specific classification or regression head. These encoders and decoders can, and often are, arranged in all sorts of ways, but here I'll describe a basic transformer encoder.
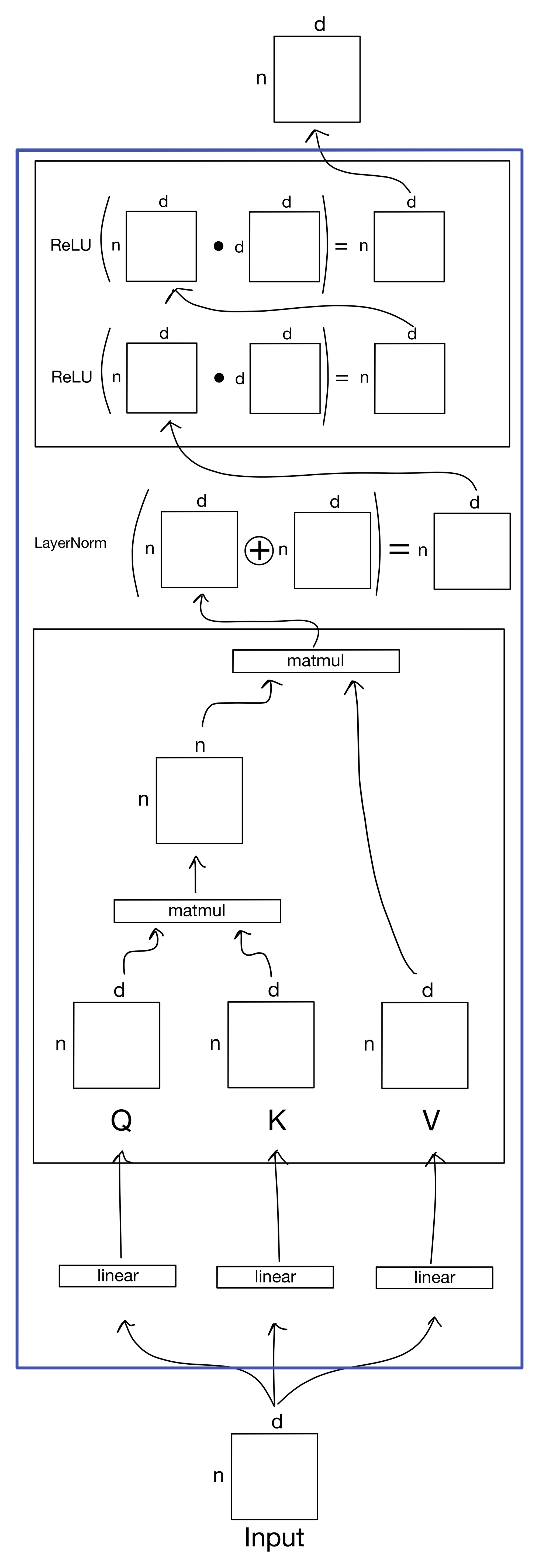
The encoder consists of a stack of attention layers. Each attention layer is composed of the following sublayers: multi-head attention, addition and layer norm, and feed-forward sublayers.
First, the input goes into the multi-head attention sublayer, which is exactly as described previously in last weeks post and beginning of this post. The resulting output is then added to the residual input and a LayerNorm operation is performed. Layer normalization is identical to batch correction, except instead of acting on the sample dimension n, LayerNorm normalizes the feature dimension d. Finally, this output is passed into the feed forward sublayer, which is comprised of two linear transformations with ReLU activations.
The transformer encoder is just a giant stack of these attention layers described above that repeats an arbitrary number S times.
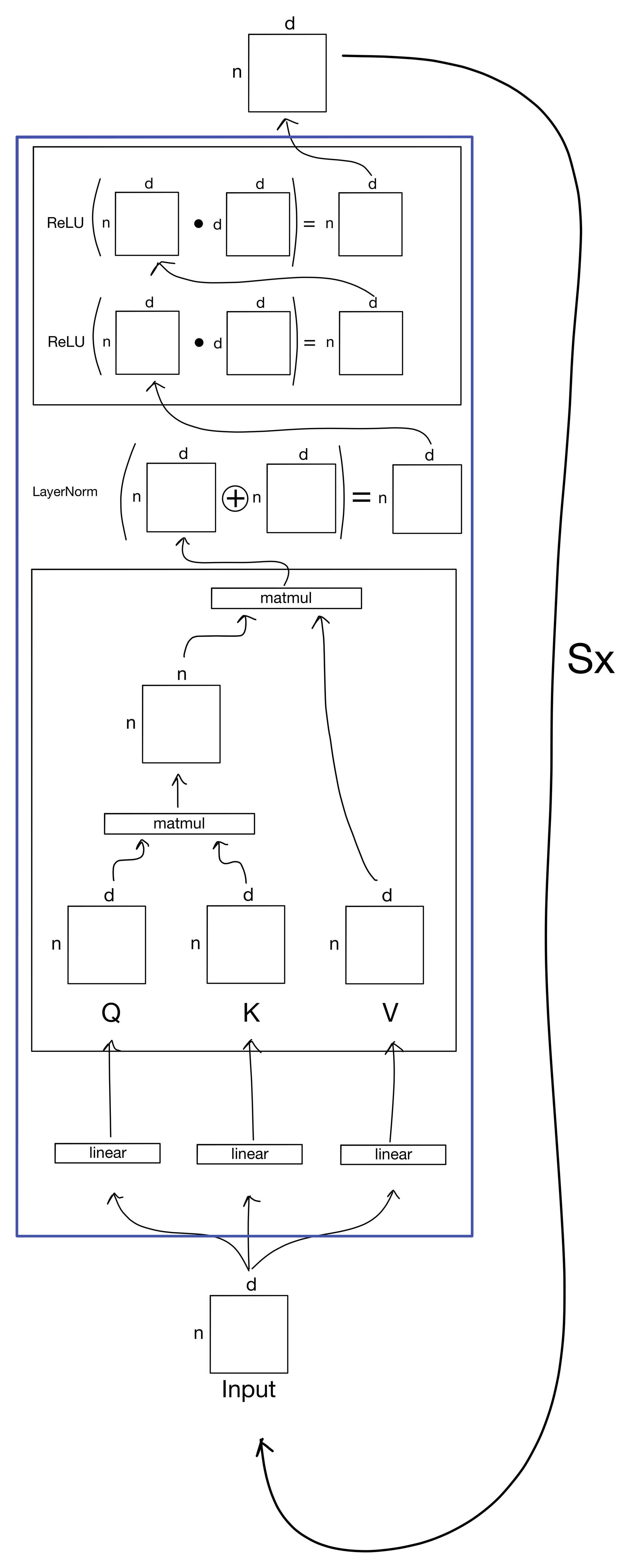
The output of the encoder can then be used for a variety of machine learning tasks. Oftentimes, Transformers will also have specialized decoders for tasks like machine translation (as in the original Transformer paper[1]). But I'll leave that for another post.
Hopefully you found this series of posts on multi-head attention useful!
1. The Transformer: https://arxiv.org/abs/1706.03762