Deep learning explainer: a simple single cell classification model
I go through a paired code/text explainer for a basic, from-the-ground-up deep learning model to classify single cell data. The goal here is to cover some basic deep learning theory, with code to go along.


Trying something new with this post.
Here, I'll go through a paired code/explainer for a basic, from-the-ground-up deep learning model to classify single cell data. The goal here is to cover some basic deep learning theory with code to go along.
This walkthrough is also available as a Google Colab notebook here
(I would encourage looking at the Colab notebook, it has the same information and is a better experience.)
Lets go
!pip install scanpy
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import scanpy as sc
import torch
import umap
from sklearn.preprocessing import OneHotEncoder
from sklearn.metrics import confusion_matrixThe goal of any good deep learning model is to accomplish some task and/or extract useful information from input data. This could take several forms, such as classifying, clustering, or embedding (i.e. generating new features for) the input samples.
We tell the model how to extract the information we want it to through defining a loss function.
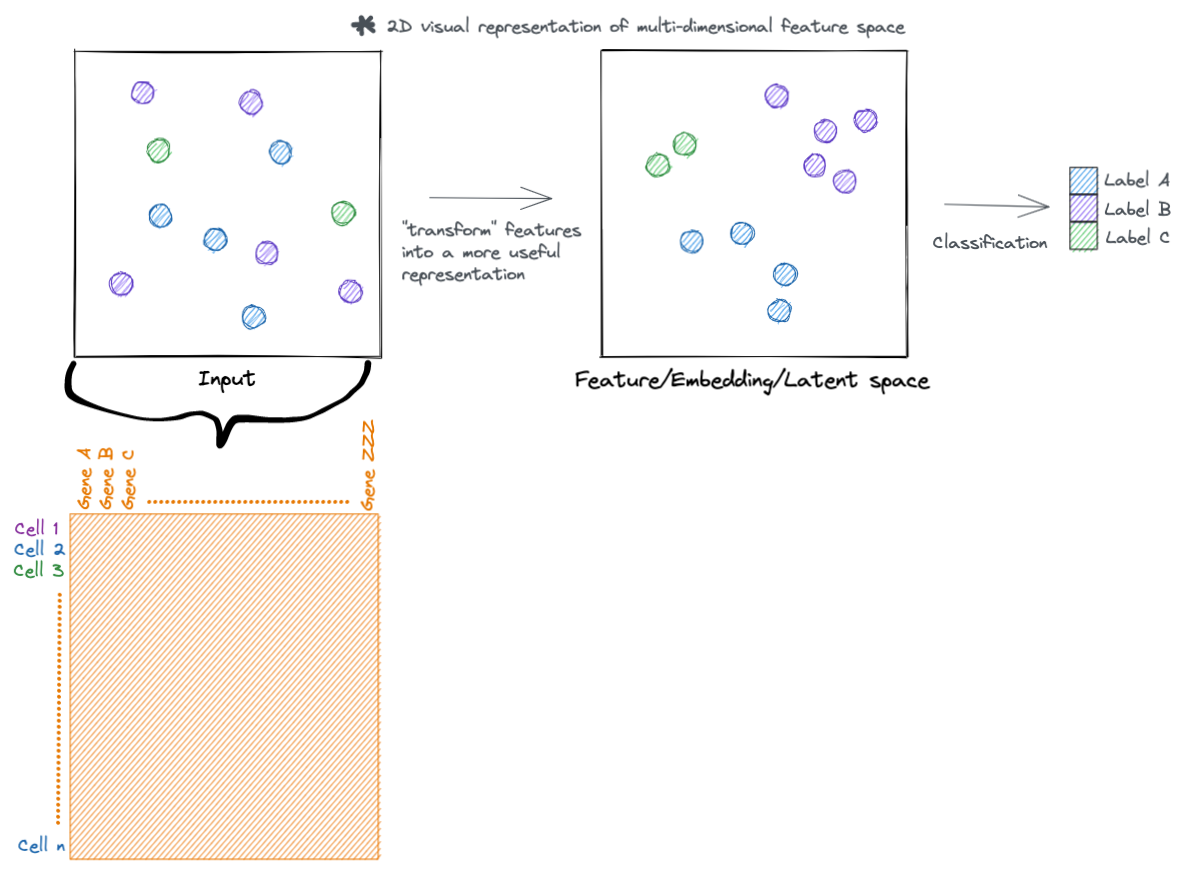
At a high level, neural networks accomplish their task by transforming input features into more useful representations. Below is an example of a hypothetical dataset where we go from input features that are not meaningful to the task at hand (such as clustering samples by type), to a representation that is more meaningful (the samples separate by type). You can call this new representation by a lot of names (feature space, embedding space, latent space, etc.). But the main idea is that this new transformed feature space is more meaningful to the task to be accomplished.
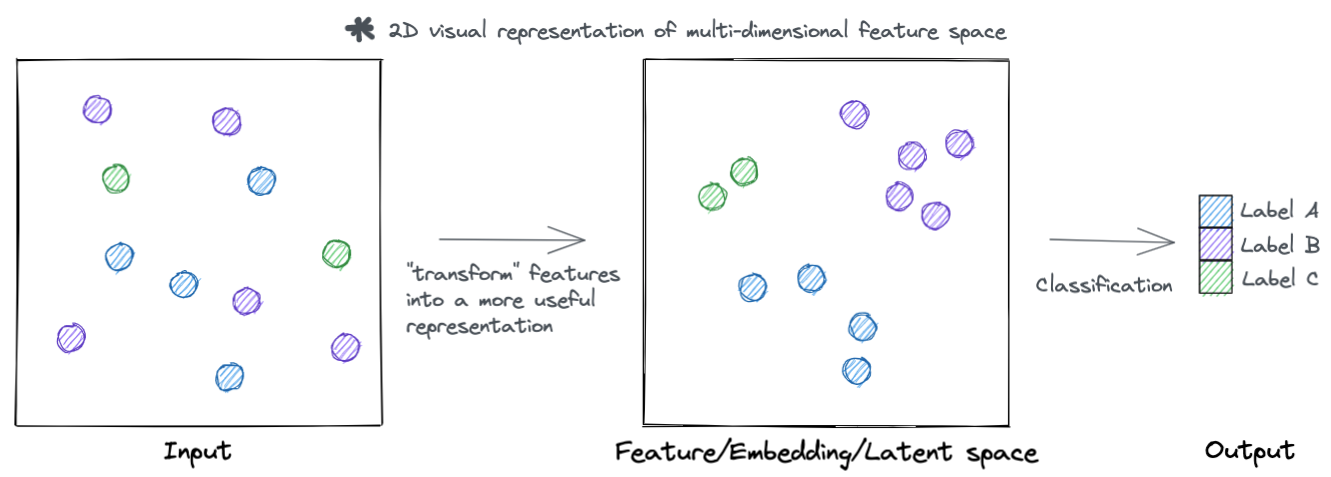
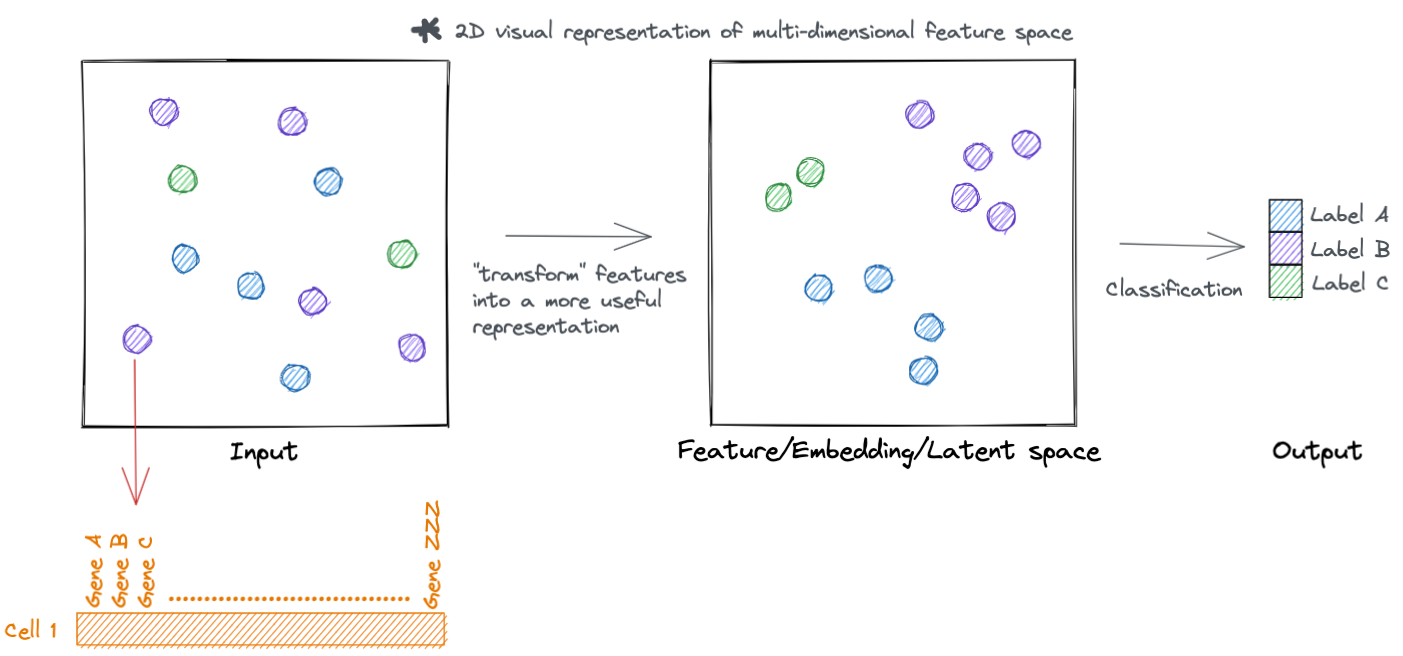
Lets go a little deeper, rather then just visualizing these hypothetical samples. Each sample has a set of features that describe it. For example, in single cell data each cell (sample) has a set of genes (features) that describe it.
These features are represented as tensors, which is just a fancy name for a vector (i.e. collection of numeric values associated with a sample).
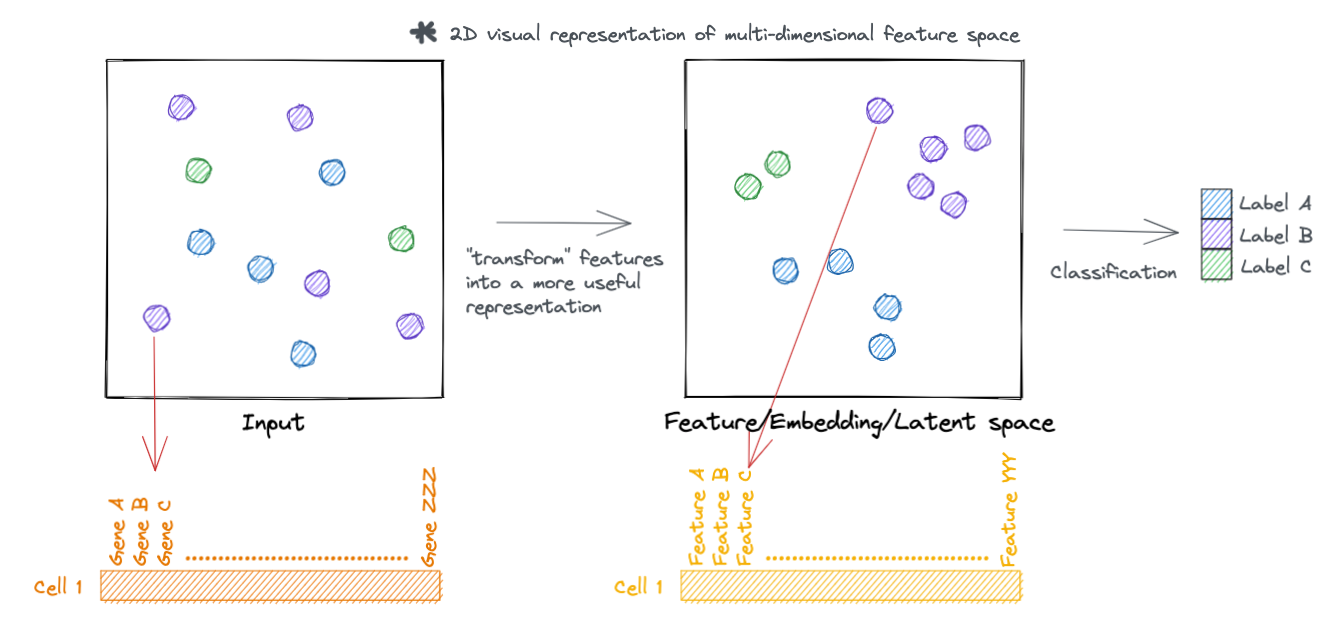
Similarly, we can represent the transformed feature space as a tensor.
A code walkthrough: Simplified Pollock
Pollock is a single cell classification tool. Here we'll make a simplified version from the ground up.
In doing so, we will (hopefully) build an intuition for basic machine learning data preprocessing and deep learning.
Data preprocessing
We'll use the PBMC3K dataset that ships with the Scanpy single cell analysis library.
def get_pbmc_dataset():
adata = sc.datasets.pbmc3k()
processed = sc.datasets.pbmc3k_processed()
overlap = sorted(set(adata.obs.index).intersection(set(processed.obs.index)))
adata, processed = adata[overlap], processed[overlap]
adata.obs['label'] = processed.obs['louvain'].to_list()
return adata
adata = get_pbmc_dataset()
adata
Basic single cell preprocessing
- Filter genes/cells with minimal transcript counts and high mitochondrial content
- normalize to total counts per cell
- log2 + 1
- scale genes between 0-1
sc.pp.filter_cells(adata, min_genes=200)
sc.pp.filter_genes(adata, min_cells=3)
adata.var['mt'] = adata.var_names.str.startswith('MT-') # annotate the group of mitochondrial genes as 'mt'
sc.pp.calculate_qc_metrics(adata, qc_vars=['mt'], percent_top=None, log1p=False, inplace=True)
adata = adata[adata.obs.n_genes_by_counts < 2500, :]
adata = adata[adata.obs.pct_counts_mt < 5, :]
sc.pp.normalize_total(adata, target_sum=1e4) # normlize to total counts per cell
sc.pp.log1p(adata) # log2 + 1
sc.pp.scale(adata) # scale genes by unit variance and zero to meanTraining vs. Test data
For our purposes today we'll split our single cell data into two datasets: a training and a validation dataset. The training dataset is what the model will learn on, while the validation dataset will be what we use to calculate validation metrics to see how well the model is learning.
We won't do this today, but it is also a good idea, to have a test or validation dataset that consists of cells that are from biological samples not in the training dataset. Here for simplicity we are violating that rule because all cells in the PBMC3K dataset are from the same sample.
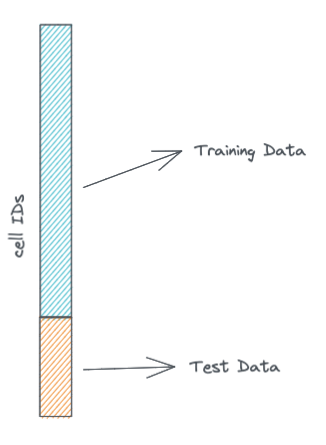
split = .8 # we take 80% of the cells for the training dataset, the rest will be in the validation dataset
train_barcodes = np.random.choice(adata.obs.index, replace=False, size=int(split * adata.shape[0]))
val_barcodes = np.asarray([barcode for barcode in adata.obs.index if barcode not in set(train_barcodes)])
len(train_barcodes), len(val_barcodes)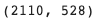
train_adata = adata[train_barcodes]
val_adata = adata[val_barcodes]
train_adata.shape, val_adata.shape # (n_cells x n_genes)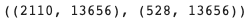
The input features
Here we set our training and validation input data. The data matrices are both n_cells x n_genes (cells are rows, genes are columns).
X_train = train_adata.X
X_val = val_adata.X
X_train.shape, X_val.shape # (n_cells x n_genes)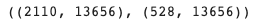
The target variable
The target variable is the variable we want the model produce (cell type in this case).
There are seven possible cell type labels.
labels = sorted(set(adata.obs['label']))
labels
Each of which is assigned to a cell in the training dataset.
adata.obs[['label']]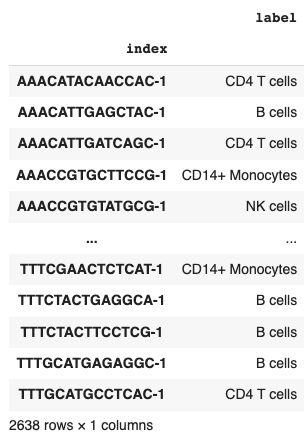
Usually, machine learning libraries expect numerical values instead of strings when specifying labels.
For multi-label classification, this is typically done via a one-hot encoding.
A one-hot encoding is a binary matrix where each row is a sample and each column is a possible label (cell types in this case). Each row will have all 0s except for one value which is a 1. This 1 indicates the label for that sample.
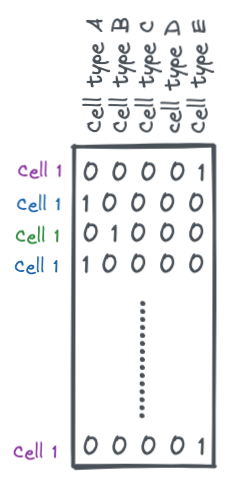
encoder = OneHotEncoder()
encoder.fit(adata.obs['label'].to_numpy().reshape(-1, 1))
y_train = encoder.transform(train_adata.obs['label'].to_numpy().reshape(-1, 1)).toarray()
y_val = encoder.transform(val_adata.obs['label'].to_numpy().reshape(-1, 1)).toarray()
y_train.shape, y_val.shape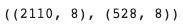
labels = encoder.categories_[0]
labels
y_train
Making the dataloader
PyTorch, the Python library we will be using, has abstractions for a Dataset and Dataloader. These objects help feed training and validation data into the neural network during training.
# first we need to make our model inputs tensors
X_train, X_val = torch.tensor(X_train), torch.tensor(X_val)
y_train, y_val = torch.tensor(y_train), torch.tensor(y_val)train_dataset = torch.utils.data.TensorDataset(X_train, y_train)
val_dataset = torch.utils.data.TensorDataset(X_val, y_val)During neural network training, data is fed into the network in batches, which are small subsets of the input data. There are other multiple reasons for doing this, but mainly it helps alleviate memory issues that would be caused in datasets with large numbers of samples.
During an iteration of training, every batch is fed through the model. Each iteration is known as an epoch. Models are typically trained for several epochs.
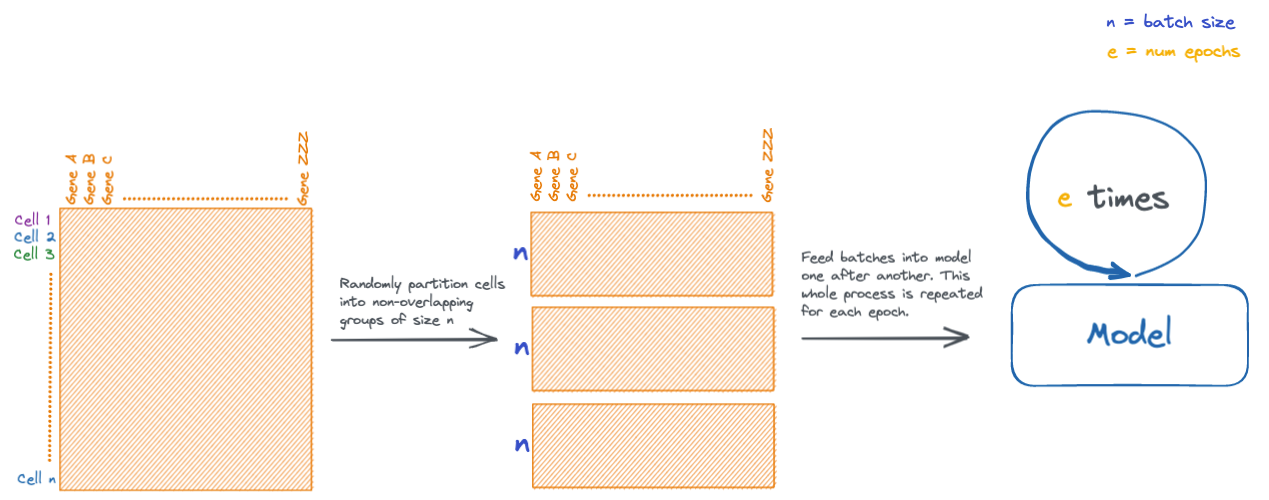
# the PyTorch dataset is used to make a DataLoader
batch_size = 64
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size)# we can inspect the contents of one batch
# the first output are the input features, the second are the class labels
b_X, b_y = next(iter(train_dataloader))
b_X.shape, b_X # feature size should be batch_size X num_genes
b_y.shape, b_y[0] # one-hot encoded matrix, should be batch_size X num_labels
Building the model
A neural network transforms inputs using weights. Weights are the values used to transform inputs to each layer in the network. Thing of the weights as being somewhat analogous to the principle components in a PCA, in that principle components are used to project inputs into a different feature space.
Different types of neural network layers have different twists on this process, but the general idea of projecting inputs into a different feature still holds.
Below is the formula for a simple linear layer.
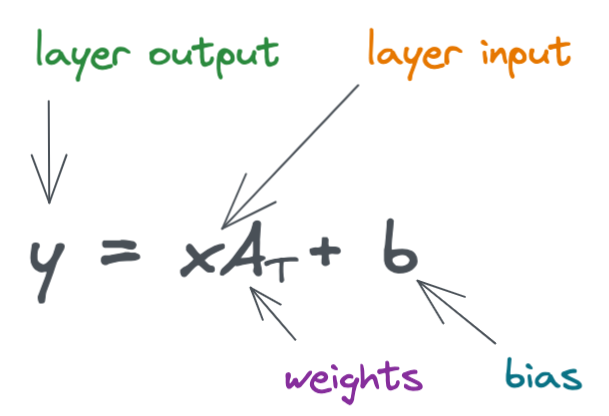
Here, we look a simple diagram of a neural network with two linear layers. (Remember that neural networks typically contain many layers, I'm showing just two layers in the following example for simplicity).
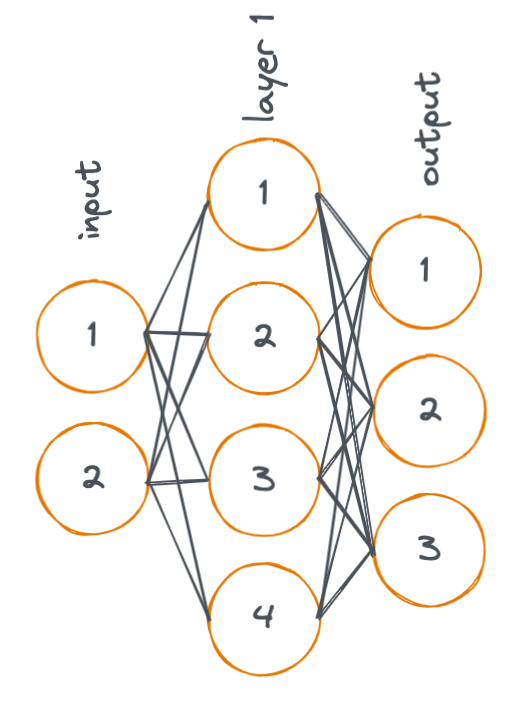
In the diagram, each node represents an activation, and each line represents a weight. An activation is a value that is input (or output) to/from a layer in the neural network.
Let's take an example problem where we would like to apply a neural network to .... fruit!
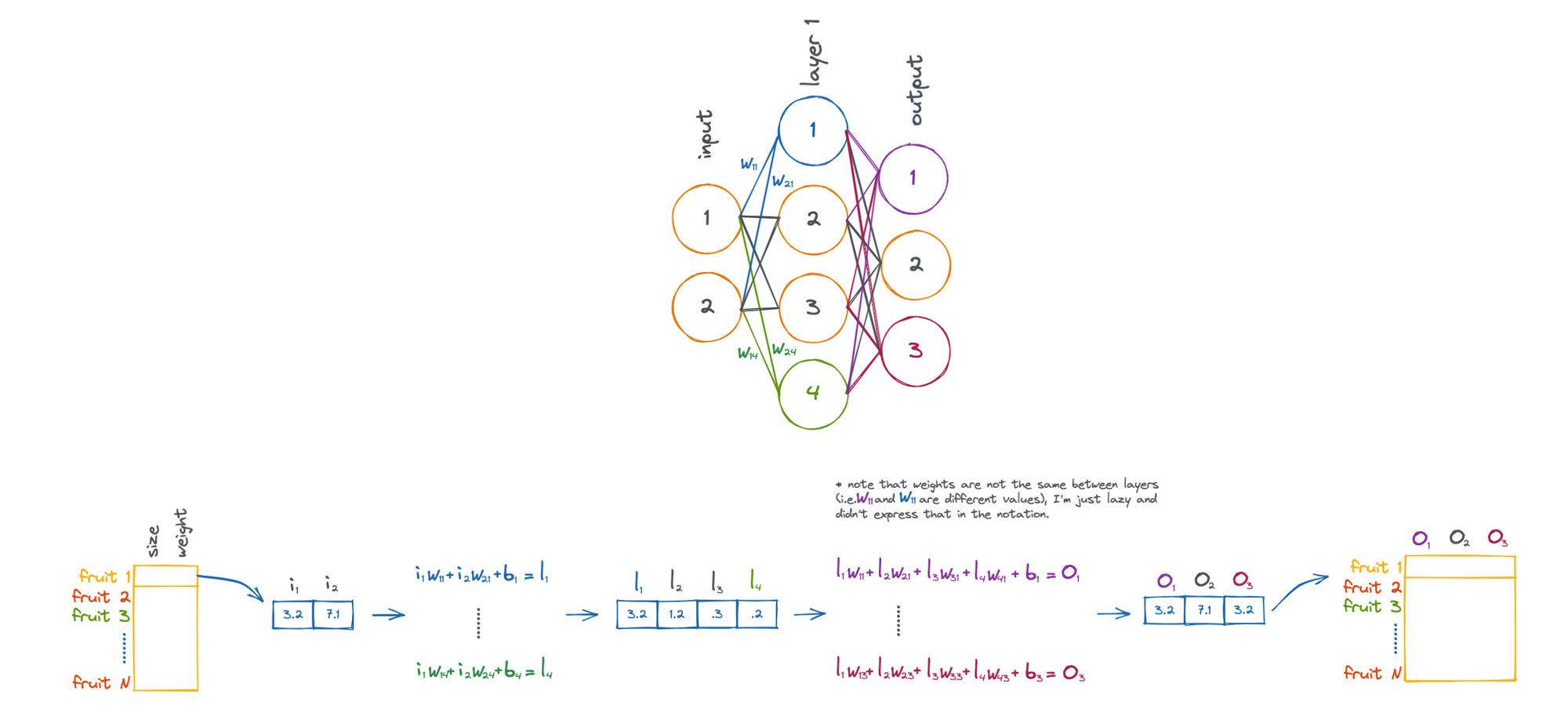
Above shows the process of taking a piece of fruit that has two input features (size and weight), and passing it through the neural network until we have an output that is in 3-dimensional feature space (O1, O2, and O3).
Note that the weights (W) and biases (b) are what influence how the fruit is transformed. These values are what are updated by the neural network in attempt to accomplish a given task.
So, when we talk about a neural network "learning", what we mean is that it is updating its internal weights and biases. Collectively, weights and biases are known as parameters of the network. Modern neural networks can scale to have billions of parameters!
Now that we have a general feel for the math of linear layers, we can cast the above process as a series of matrix operations, allowing us to pass multiple samples through the network simultaneously.

More generally, we can formulate a linear layer as the following.
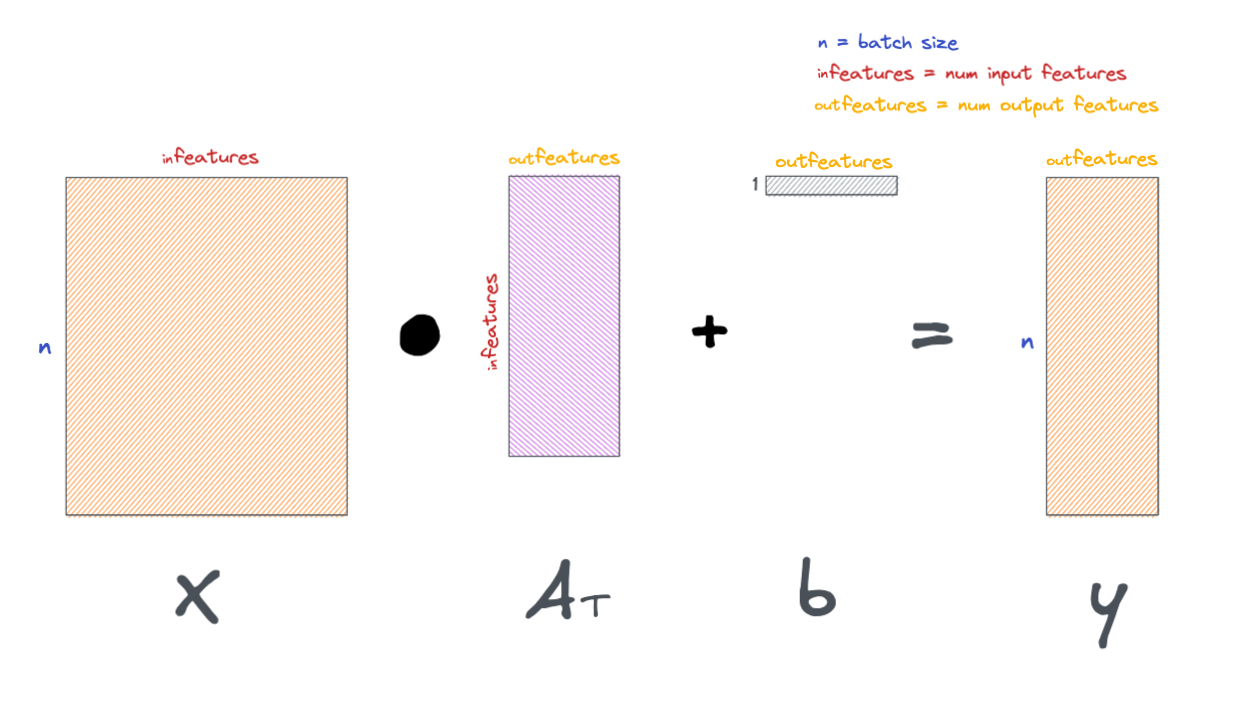
These layers are visually represented in a variety of ways, below are a few examples.
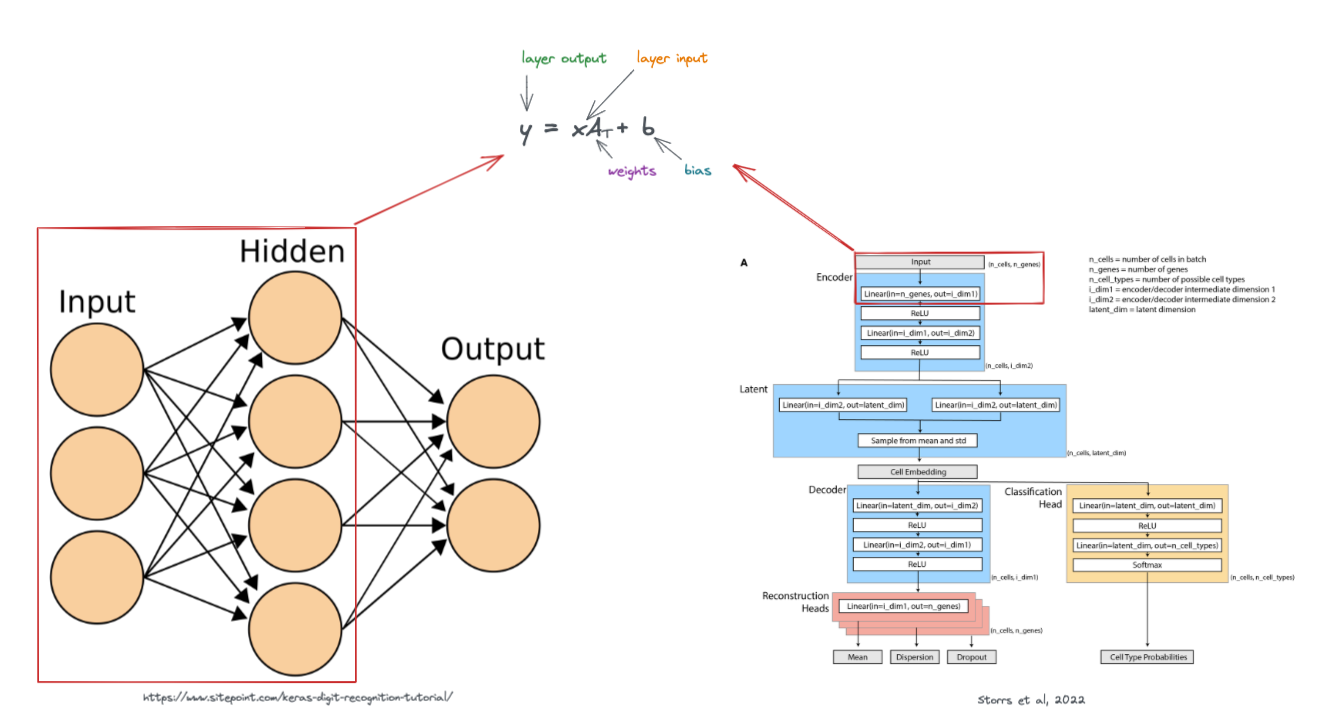
The weights of a network (also known collectively as parameters), control what type of outputs the model gives. As the model learns, it updates it's weights, allowing it to make better predictions.
There's one more thing to mention about layers in neural networks, typically, they are followed by a non-linear activation function.
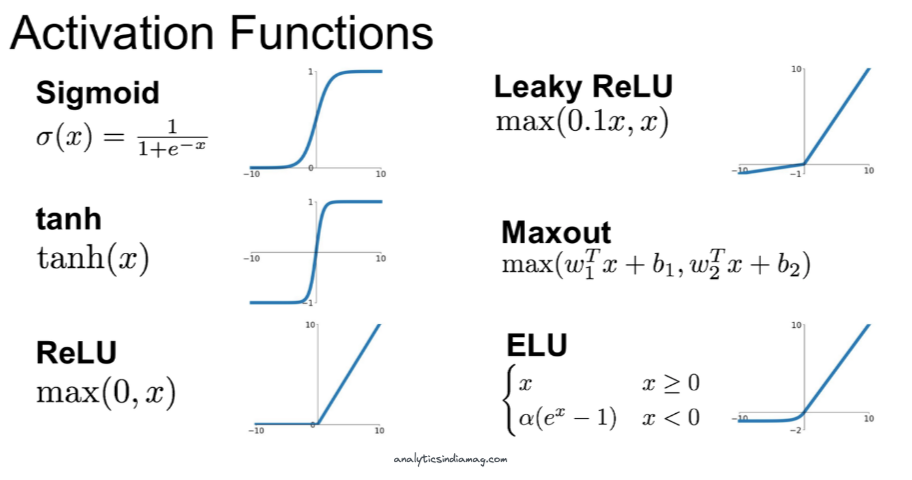
Each one of these non-linear functions alters the output values of each layer in a non-linear fashion. For example, if we take the rectified linear unit (ReLU) activation function, any values in output of a layer <0 be set to zero, and all values >0 will remain the same.
That's all there is to a linear layer. There are other types of layers too, such as convolutional layers used in imaging, but we'll save those for the future.
Here, we initialize a simple linear layer with PyTorch and see it in action.
n_genes = X_train.shape[1]
out_features = 128
layer = torch.nn.Linear(in_features=n_genes, out_features=out_features)
layer
We can test drive this layer by feeding one of our input batches defined earlier.
Also, a quick note: the outputs of each layer throughout the network are known as activations.
activations = layer(b_X) # feed inputs through layer
activations = torch.functional.F.relu(activations) # put layer outputs through ReLU non-linear function.
activations.shape, activations
Below is a schematic of the operations we just did in the above notebook cell.
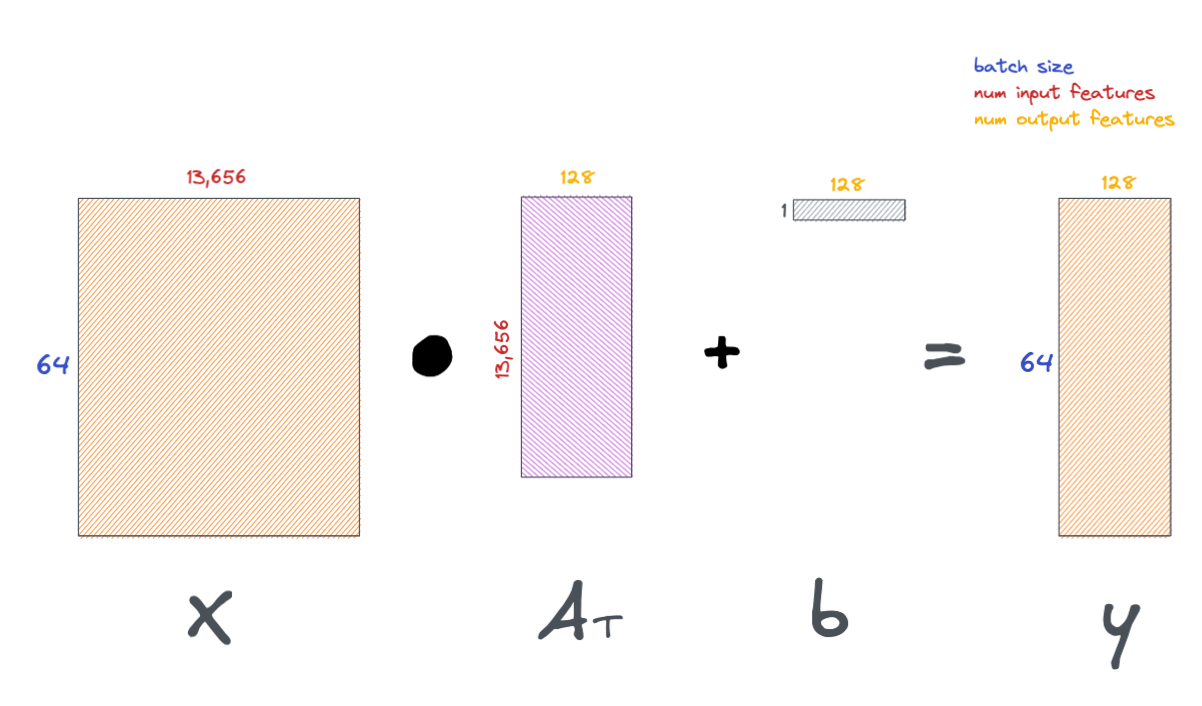
The loss function
There's one last piece before we can build an actual model. The loss function.
Loss functions define what we want the model to do.
If we want the model to classify something, the loss function will be related to label classification. If we want to cluster something, the loss function will probably be related to constraining one of the hidden layers of the model in some way. There is no limit to the number/type/variety of loss functions you can use in a model. This is part of what makes deep learning so powerful.
More complex loss functions are out of scope for this notebook, but we will cover the popular cross-entropy loss function. This is the main loss function used for multi-label classification problems (which is what we need here, as a cell could be classified as one of many different cell types).
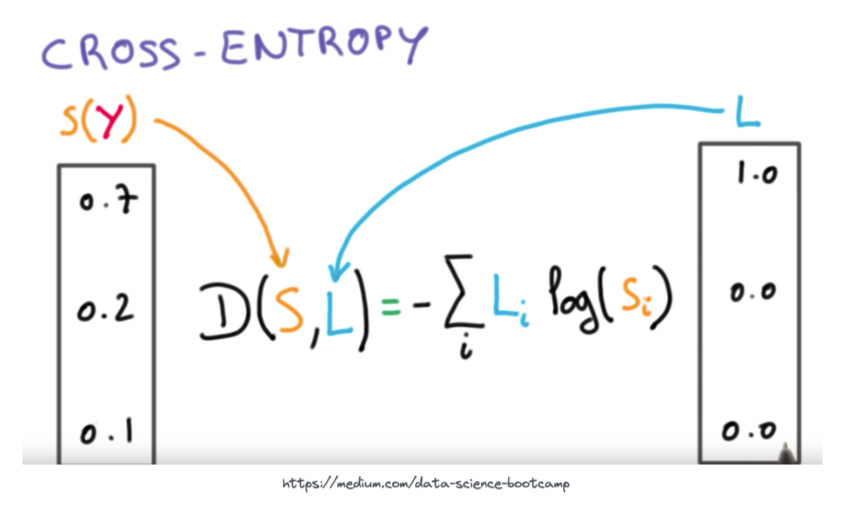
The essence of the above equation is that we are comparing the output probabilities of the neural network S to the actual ground-truth target probabilities L. For an intuitive visual on how the output of the cross-entropy loss function looks with increasing difference between predicted and target values see the plot below.
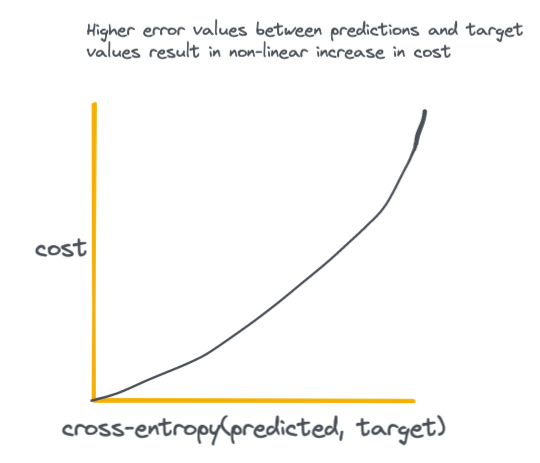
The key takeaway here is that high loss values disproportionately result in higher cost to the network, which incentives the network to do everything it can to achieve the smallest possible difference between predicted and target values.
Output probabilities
So how do we get output probabilities to feed into the cross-entropy loss function in the first place?
We use a function called Softmax. The softmax function is applied to the last layer of the neural network. It's job is to convert the activations from the last layer of the neural network to probabilities.
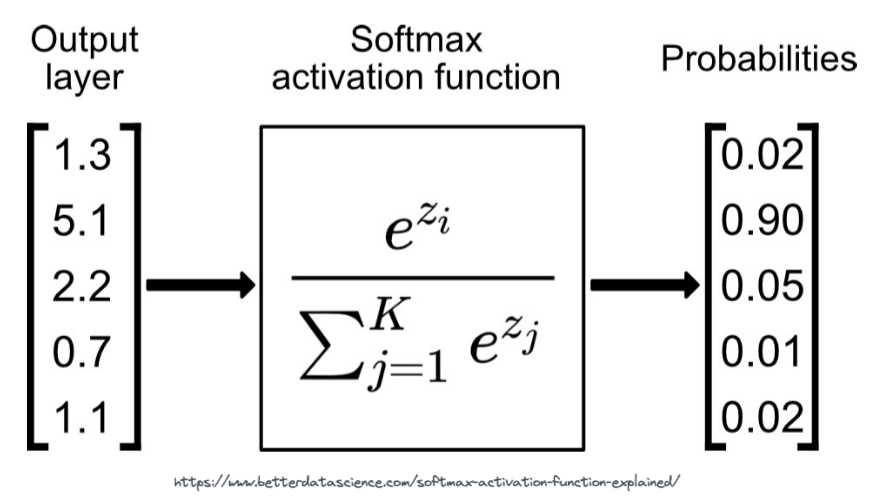
# we can test the above with the PyTorch softmax function
x = torch.tensor([1.3, 5.1, 2.2, 0.7, 1.1])
torch.functional.F.softmax(x)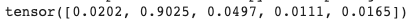
Notice how the softmax function squishes/sharpens the activations of the final layer while simultaneously making them add up to 1.
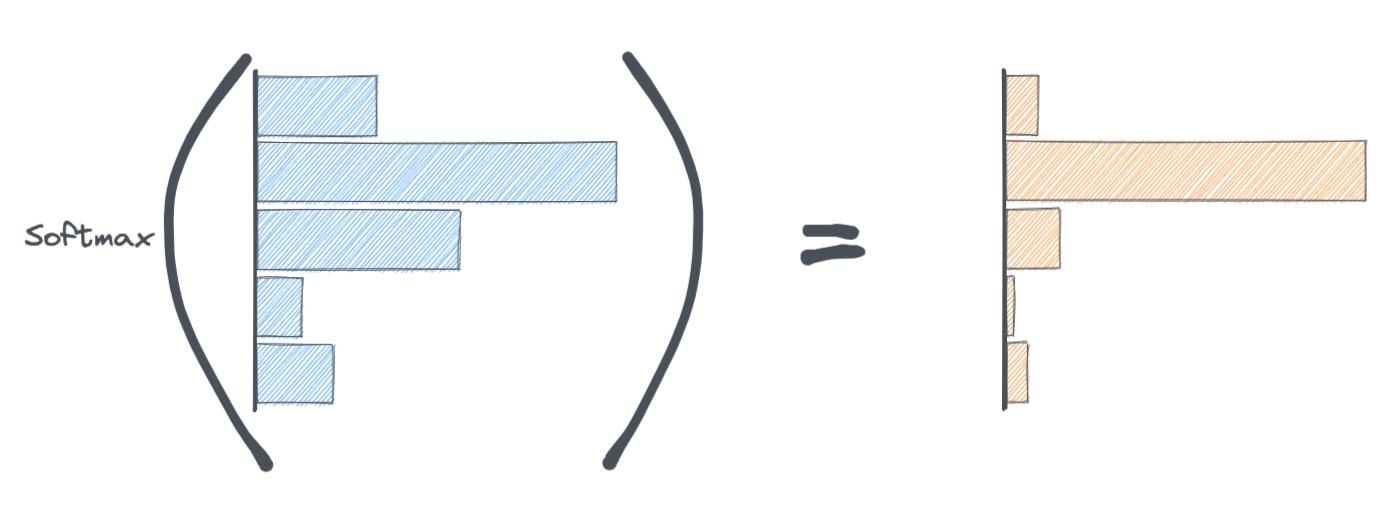
This probability distribution is ultimately what goes into the cross-entropy loss function.
Putting it all together
Next, we'll create a model using the components we discussed above
- Multiple linear layers
- Softmax layer
- cross-entropy loss
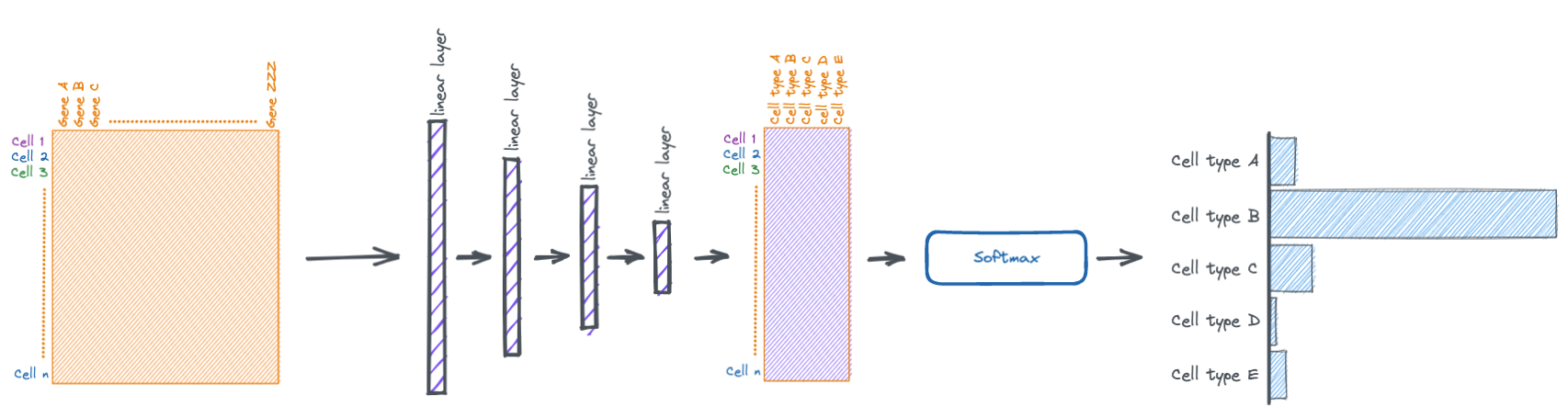
The torch.nn.Module class in PyTorch makes it easy to stack multiple layers together.
Here we make a simple four layer network.
Some things to take note of:
- the number of input features for a layer must match the number of output features of the previous layer.
- the last linear layer must output activations that are the same length as the number of possible cell types. this is because those activiations will be turned into a probability distribution by the softmax function, so each position in the tensor will be a probability for a specific cell type.
- we also apply dropout between the first couple layers. dropout is a technique where random activations are set to zero with some probability (usually 20-50%) during training. this helps with generalizaing the model to data it hasn't seen before.
class SimplePollock(torch.nn.Module):
def __init__(self, n_genes, n_labels):
super(SimplePollock, self).__init__()
self.n_genes = n_genes # number of genes in input
self.n_labels = n_labels # number of possible cell types
self.layers = torch.nn.Sequential(
torch.nn.Linear(in_features=n_genes, out_features=1028), # layer 1
torch.nn.ReLU(),
torch.nn.Dropout(p=.2), # randomly zero 20% of input tensor, helps with generalization
torch.nn.Linear(in_features=1028, out_features=256), # layer 2
torch.nn.ReLU(),
torch.nn.Dropout(p=.2), # randomly zero 20% of input tensor, helps with generalization
torch.nn.Linear(in_features=256, out_features=128), # layer 3
torch.nn.ReLU(),
)
self.final_layer = torch.nn.Sequential(
torch.nn.Linear(in_features=128, out_features=self.n_labels), # output layer must be the same length as the total number of classes
torch.nn.Softmax(dim=1), # creates prediction probabilities
)
self.loss_function = torch.nn.CrossEntropyLoss() # we will use cross entropy loss
def calculate_loss(self, predicted, target):
return self.loss_function(predicted, target) # use cross entropy to calculate loss
def final_activations(self, x):
"""Return activations of second to last layer"""
return self.layers(x)
def forward(self, x):
"""
Defines how activations are propogated through the network.
In our case, they go through four layers followed by a softmax function.
"""
x = self.layers(x)
x = self.final_layer(x)
return x
model = SimplePollock(n_genes, len(labels))
model
We can do a sanity check and test run some data through the model.
probs = model(b_X)
probs.shape, probs[0] # view output shape and probabilities for first cell in batch
Here we define some model hyperparameters. Hyperparameters are model parameters that influence how the model trains/behaves. For example, the number of epochs (i.e. number of times the model iterates through the training data) is a hyperparameter.
n_epochs = 10 # num of iterations we will go through the training data
lr = .0001 # learning rate, I didn't talk about it above, but think of it as controlling how fast the model updates its parameters.
optimizer = torch.optim.Adam(model.parameters(), lr=lr) # I also havent talked about optimizers, but this controls the method the model uses to update its parametersDeep learning models run faster on GPU, here we move our model to the GPU.
model = model.cuda()Below we define a training loop. Inside the loop we feed batches into our model, calculate the loss, and update model parameters.
def accuracy(y_pred, y_true):
"""helper accuracy function"""
if y_pred.is_cuda:
y_pred, y_true = y_pred.cpu().detach(), y_true.cpu().detach()
pred_labels = np.asarray([labels[i] for i in np.argmax(y_pred, axis=1)])
true_labels = np.asarray([labels[i] for i in np.argmax(y_true, axis=1)])
return np.sum(pred_labels==true_labels) / len(pred_labels)train_losses, val_losses, train_accs, val_accs = [], [], [], [] # track training history
for i in range(n_epochs):
train_loss, val_loss = 0., 0.
train_acc, val_acc = 0., 0.
# training
model.train()
for x, y in train_dataloader:
x, y = x.cuda(), y.cuda() # move inputs to GPU
optimizer.zero_grad() # optimizer gradients need to be zeroed on every batch
probs = model(x) # get output probabilities from model
loss = model.calculate_loss(probs, y) # calculate loss for predictions vs. targets
train_loss += loss.item() # add loss for batch to total training loss
train_acc += accuracy(probs, y) # add accuracy for batch to total training accuracy
loss.backward() # propogate gradients
optimizer.step() # adjust model parameters based on loss
# validation
model.eval()
with torch.no_grad(): # we dont want to update parameters during validation.
for x, y in val_dataloader:
x, y = x.cuda(), y.cuda() # move inputs to GPU
probs = model(x) # get output probabilities from model
loss = model.calculate_loss(probs, y) # calculate loss for predictions vs. targets
val_loss += loss.item() # add loss for batch to total validation loss
val_acc += accuracy(probs, y) # add accuracy for batch to total validation accuracy
# scale metrics to total number of batches
train_loss /= len(train_dataloader) # scale to total number of batches
val_loss /= len(val_dataloader) # scale to total number of batches
train_acc /= len(train_dataloader) # scale to total number of batches
val_acc /= len(val_dataloader) # scale to total number of batches
train_losses.append(train_loss)
val_losses.append(val_loss)
train_accs.append(train_acc)
val_accs.append(val_acc)
# print metrics for epoch
print(f'Epoch: {i}, Train loss: {train_loss}, Val loss: {val_loss}, Train acc: {train_acc}, Val acc: {val_acc}')
Plotting the training/validation loss and and accuracy over time.
source = pd.DataFrame.from_dict({
'Epochs': list(range(n_epochs)),
'train_loss': train_losses,
'val_loss': val_losses,
'train_accuracy': train_accs,
'val_accuracy': val_accs
})plt.plot(source['Epochs'], source['train_loss'], label='train loss')
plt.plot(source['Epochs'], source['val_loss'], label='validation loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()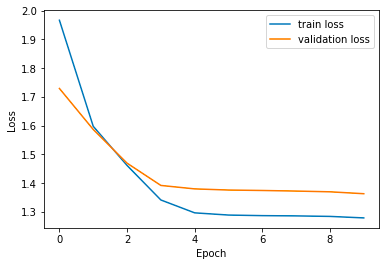
plt.plot(source['Epochs'], source['train_accuracy'], label='train accuracy')
plt.plot(source['Epochs'], source['val_accuracy'], label='validation accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()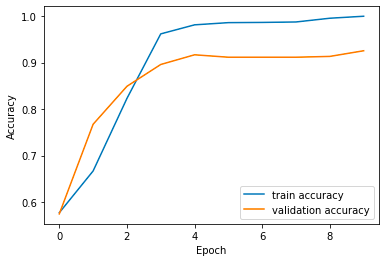
Let's get predictions for the training and validation datasets from the trained model.
with torch.no_grad():
train_probs = model(X_train.cuda()).cpu().detach()
val_probs = model(X_val.cuda()).cpu().detach()
train_probs.shape, train_probs[0] # There are 8 probabilities, one for each possible cell type. Should be n_cells X n_labels.
Viewing the validation classifications.
def get_confusion_matrix(y_pred, y_true, normalize=None):
"""helper accuracy function"""
if y_pred.is_cuda:
y_pred, y_true = y_pred.cpu().detach(), y_true.cpu().detach()
pred_labels = np.asarray([labels[i] for i in np.argmax(y_pred, axis=1)])
true_labels = np.asarray([labels[i] for i in np.argmax(y_true, axis=1)])
df = pd.DataFrame(
data=confusion_matrix(true_labels, pred_labels, labels=labels, normalize=normalize),
index=labels, columns=labels)
df.index.name = 'Groundtruth'
df.columns.name = 'Predicted'
return dfget_confusion_matrix(val_probs, y_val)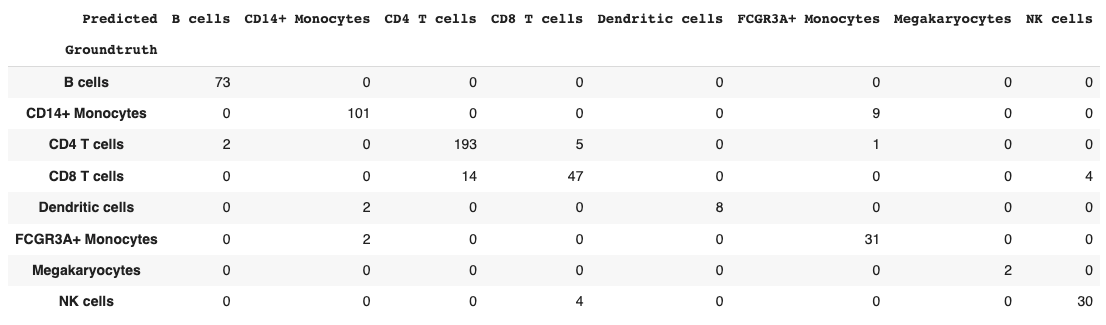
import seaborn as sns
sns.heatmap(get_confusion_matrix(val_probs, y_val, normalize='true'), cmap='viridis')
Seems that most of the model confusion is between CD4 vs. CD8 T cells and between Dendritic cells and Monocytes, which makes biological sense.
At the beginning of the notebook I mentioned that you can think of the layers of the neural network as making more and more meaningful transformations. We can attempt to view those transformations via dimensionally reduction.
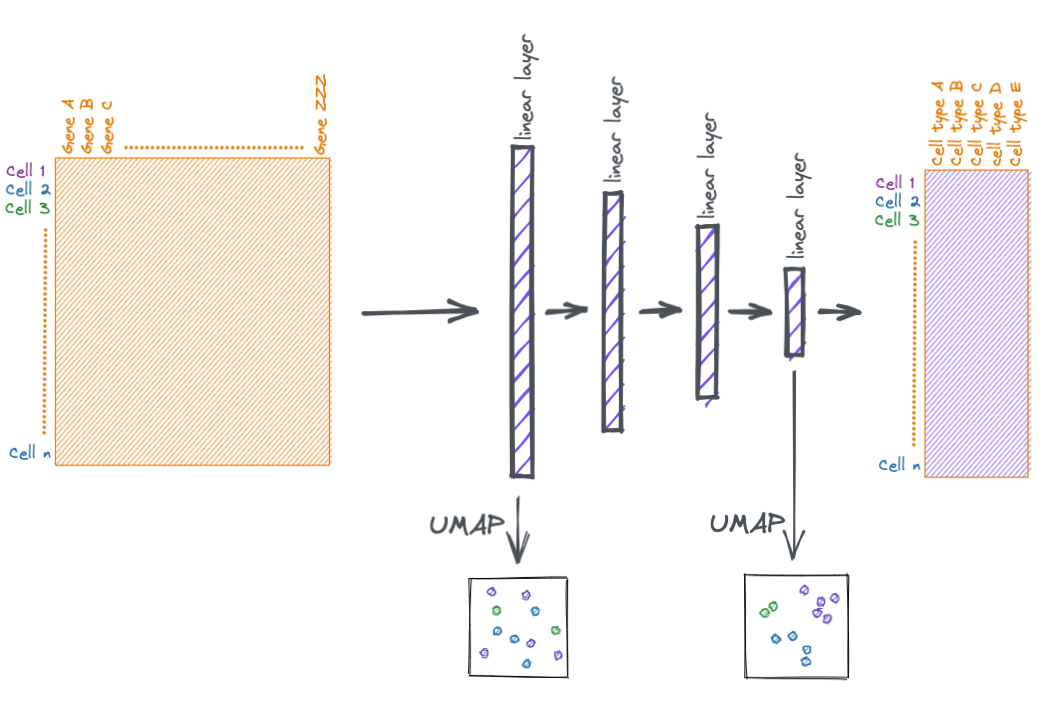
Below we take the output from the second to last layer and plot it via UMAP.
with torch.no_grad():
x = model.final_activations(X_train.cuda()).cpu().detach() # get activations of intermediate layer
emb = umap.UMAP().fit_transform(x) # apply umap dim reduction
emb.shape, emb[:5] # reduced to two dimensions
train_adata.obsm['X_umap'] = emb
sc.pl.umap(train_adata, color='label')
Doing the same for the validation dataset.
with torch.no_grad():
x = model.final_activations(X_val.cuda()).cpu().detach() # get activations of intermediate layer
emb = umap.UMAP().fit_transform(x) # apply umap dim reduction
emb.shape, emb[:5] # reduced to two dimensions
val_adata.obsm['X_umap'] = emb
sc.pl.umap(val_adata, color='label')
Notice how biologically similar cells segregate together, similar to how they do in traditional single cell analysis.
Whew, that was a lot.
Fin.