Deep Learning DINOv2: Explained DINOv2 is a continuation of the original DINO framework published by Meta in 2021. It improves self-supervised visual learning by producing more semantically meaningful patch-level features—without the need for labeled training data.
Deep Learning Deep learning explainer: a simple single cell classification model I go through a paired code/text explainer for a basic, from-the-ground-up deep learning model to classify single cell data. The goal here is to cover some basic deep learning theory, with code to go along.
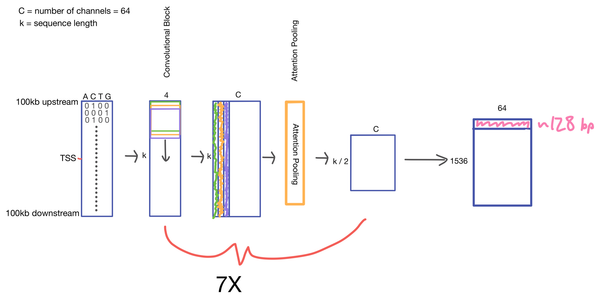
Deep Learning Enformer: Effective gene expression prediction from sequence by integrating long-range interactions Paper walkthrough of the Enformer introduced in "Effective gene expression prediction from sequence by integrating long-range interactions" by Avsec et al.
Deep Learning FixMatch, FlexMatch, and Semi-Supervised Learning (SSL) In today's post I cover semi-supervised learning (SSL), specifically in the context of the FixMatch and FlexMatch algorithms.
Deep Learning Paper Walkthrough: P-Net - a biologically informed deep neural network for prostate cancer discovery In which I cover a new biologically informed neural network architecture.
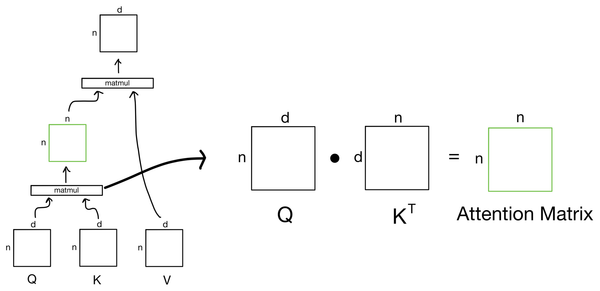
Deep Learning Featured Explained: Multi-head Attention (Part 2) Part 2 of 2 of an explanation of multi-head attention.
Deep Learning Featured Explained: Multi-head Attention (Part 1) Part 1 of 2 of a series of posts on attention in transformers. In part 1 I go over the basics of the attention mechanism.
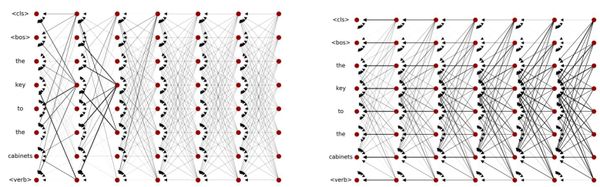
Deep Learning Explained: Attention Visualization with Attention Rollout In today's post I cover a simple method for visualization of attention in Transformers.
Deep Learning Paper Walkthrough: A Neural Algorithm of Artistic Style Where I cover one of the first deep learning algorithms for neural style transfer.
Deep Learning Explainer: CNNs and ResNets - Part 2 Part 2 of an explainer on the architecture of a convolutional neural networks and ResNets
Explainer Explainer: Convolutional Neural Networks (CNNs) - Part 1 An attempt at a visual explanation of convolutions and the basic philosophy behind convolutional neural networks (CNNs).
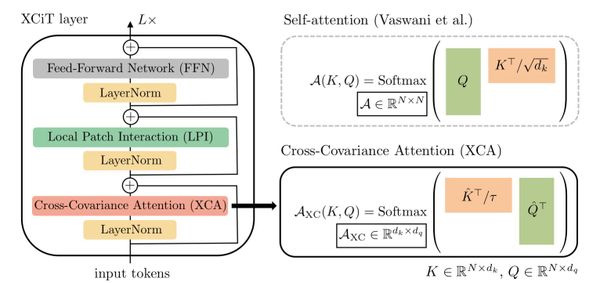
Deep Learning Paper Walkthrough: Cross-Covariance Image Transformers (XCiT) Where I cover Cross-Covariance Image Transformers (XCiT).
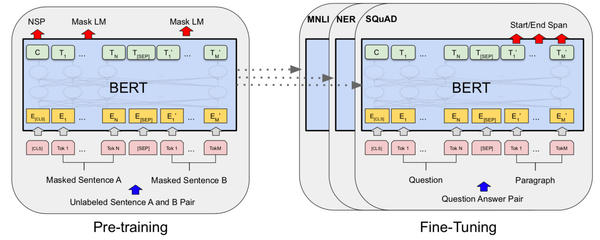
Deep Learning Paper Walkthrough: Bidirectional Encoder Representations from Transformers (BERT) This week, I cover Bidirectional Encoder Representations from Transformers (BERT).
Bioinformatics Featured Explained: Deep learning methods for scRNA-seq clustering In which I cover DESC and scDCC (a revamped version of it's predecessor scDeepCluster); two popular deep learning-based methods for embedding single cell RNA-seq (scRNA-seq) data.
Deep Learning Paper Walkthrough: DINO In this post, I'll cover Emerging Properties in Self-Supervised Vision Transformers by Caron et al., which introduces a new self-supervised training framework for vision transformers.
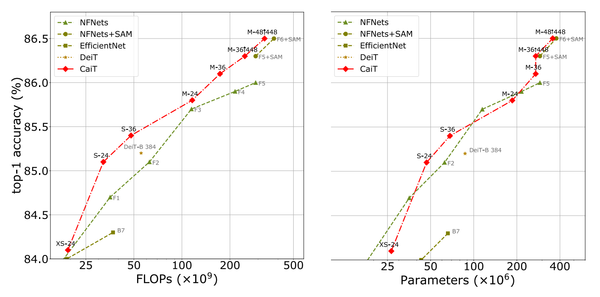
Deep Learning Paper Walkthrough: CaiT (Class-Attention in Image Transformers) In this post, I cover the paper Going deeper with image transformers by Touvron et al, which introduces LayerScale and Class-Attention Layers.
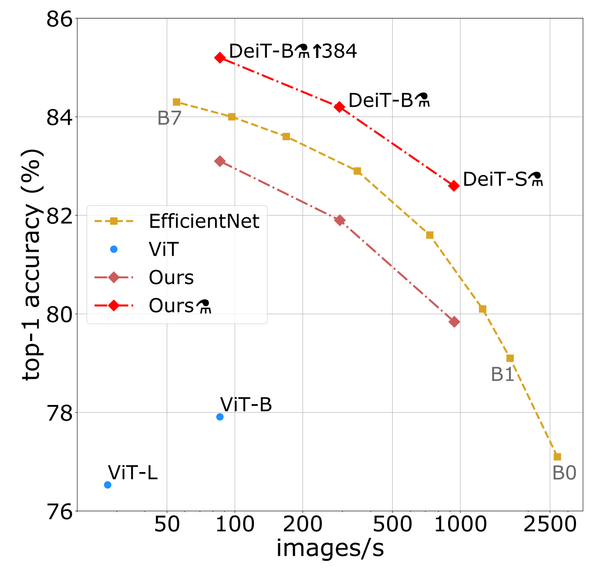
Deep Learning Featured Paper Walkthrough: DeiT (Data-efficient image Transformer) Walkthrough of the paper Training data-efficient image transformers and distillation through attention from Touvron et al. that introduces a new distillation for visual transformers.
Deep Learning Featured Paper Walkthrough: ViT (An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale) Visual walkthrough of ViT by Dosovitskiy et al. that adapts the Transformer architecture to computer vision, showing that convolutions are not necessary for SOTA performance in vision tasks.
Deep Learning Paper Walkthrough: Attention Is All You Need In this post I walk through the classic paper Attention Is All You Need