Paper Walkthrough: ViT (An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale)
Visual walkthrough of ViT by Dosovitskiy et al. that adapts the Transformer architecture to computer vision, showing that convolutions are not necessary for SOTA performance in vision tasks.


Visual walkthrough of this paper [1] by Dosovitskiy et al. that adapts the Transformer [2] architecture to computer vision, showing that convolutions are not necessary for SOTA performance in vision tasks.
Takeaways
- Attention-only architectures can be competitive with convolutional architectures for computer vision tasks. (Although convolutional methods are still better for small dataset sizes - less than ~1-10 million images - since they have inductive biases specific to image related tasks. But for larger datasets, attention shines and achieves SOTA performance.
- Transformers had previously been difficult to apply to images due to sequence lengths (images generally have many more pixels than natural language sequences do words). This method instead breaks the image up into patches, instead of pixels, which makes the transformer architecture, with its quadratic cost, feasible.
- With the further development of semi-supervised training methods, vision transformer models could be even more powerful. Models for NLP, such as GPT-3, extensively use semi-supervised learning as part of their training regimen. In theory, with more research this should be possible with visual tasks as well. Although the authors only briefly explore this topic in the paper (where they found the semi-supervised pretraining was worse than supervised pretraining).
Visual Walkthrough
Note: For the walkthrough I ignore the batch dimension of the tensors for visual simplicity.
Patch and position embeddings
A key addition here is the use of the class token ( clf , which is added in step 4 of the diagram below) that is an inherited concept from NLP. The general idea motivating the class token is that when it is passed through the transformer encoder, along with the image patch embeddings, it is forced to spread information between the patches and class token. Allowing the class token to learn to attend to useful representations of the patches, and ultimately learn an embedding that is useful for classification after it travels through the transformer encoder.
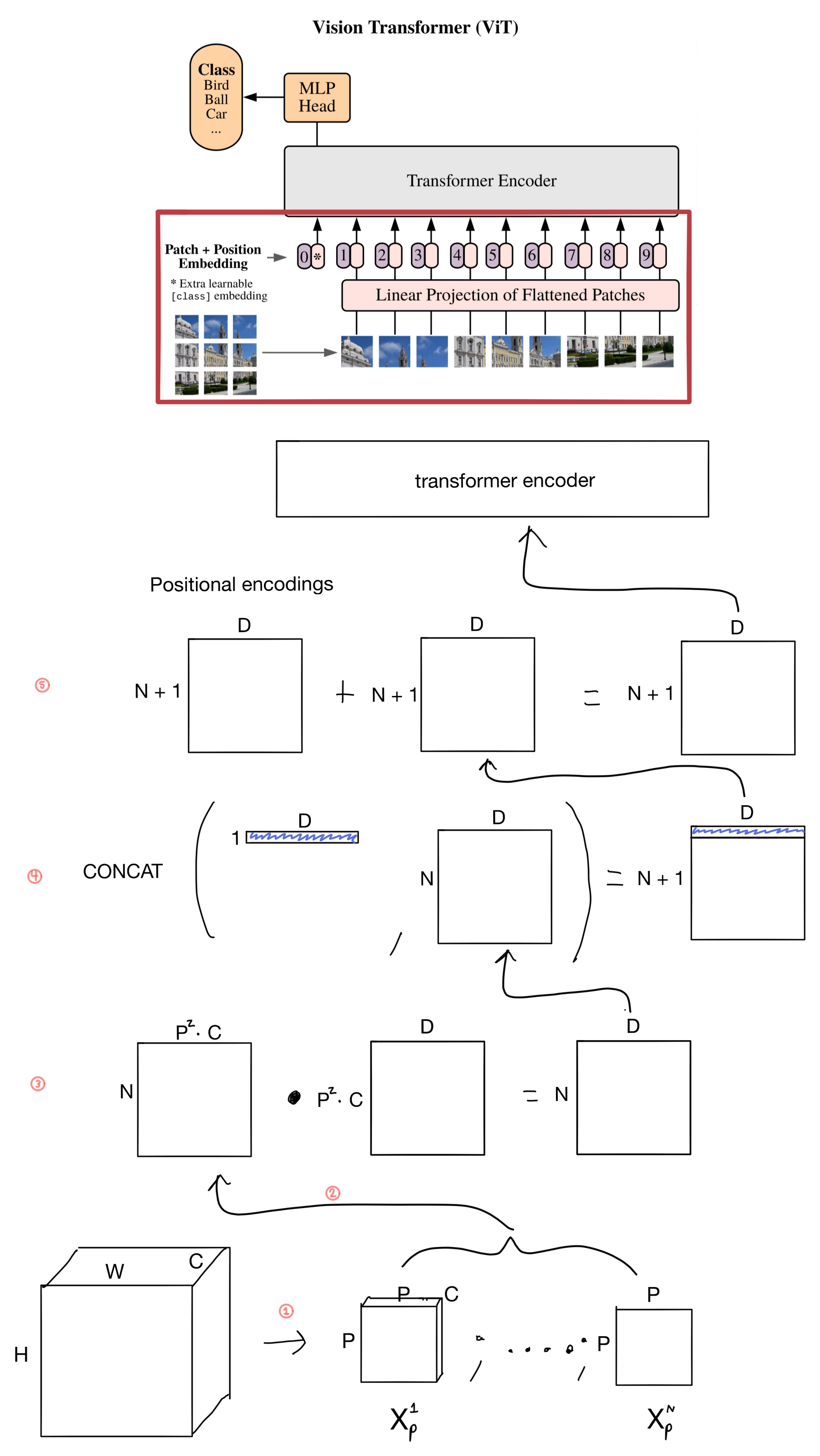
- The image of size H x W x C is unrolled into patches of size P x P x C. The number of patches is equal to H/P * W/P. For instance if the patch size is 16 and the image was 256 x 256 then there would be 16 * 16 = 256 patches.
- The pixels in each patch are flattened into one dimension.
- The patches are projected via a linear layer that outputs a latent vector of size D.
- The clf token is added to the front of the patch sequence. It is a learnable embedding of size D that will ultimately be used for classification after it is fed through the transformer. This is a similar approach that BERT [3] uses in NLP.
- Positional encodings are then added to the patches. The positional embeddings are learnable embeddings (rather than sinusoidal, like those used in the original Transformer architecture).
Transformer
I wont go into the details of the transformer for this post, but it is identical to the one used in Attention is All You Need[1]. If you're interested in the details check out my post for that paper, where I go into the details of multihead attention and Transformer encoders and decoders.
Multi-Layer Perceptron (MLP)
The MLP head is attached to the Transformer output to perform the actual classification task.
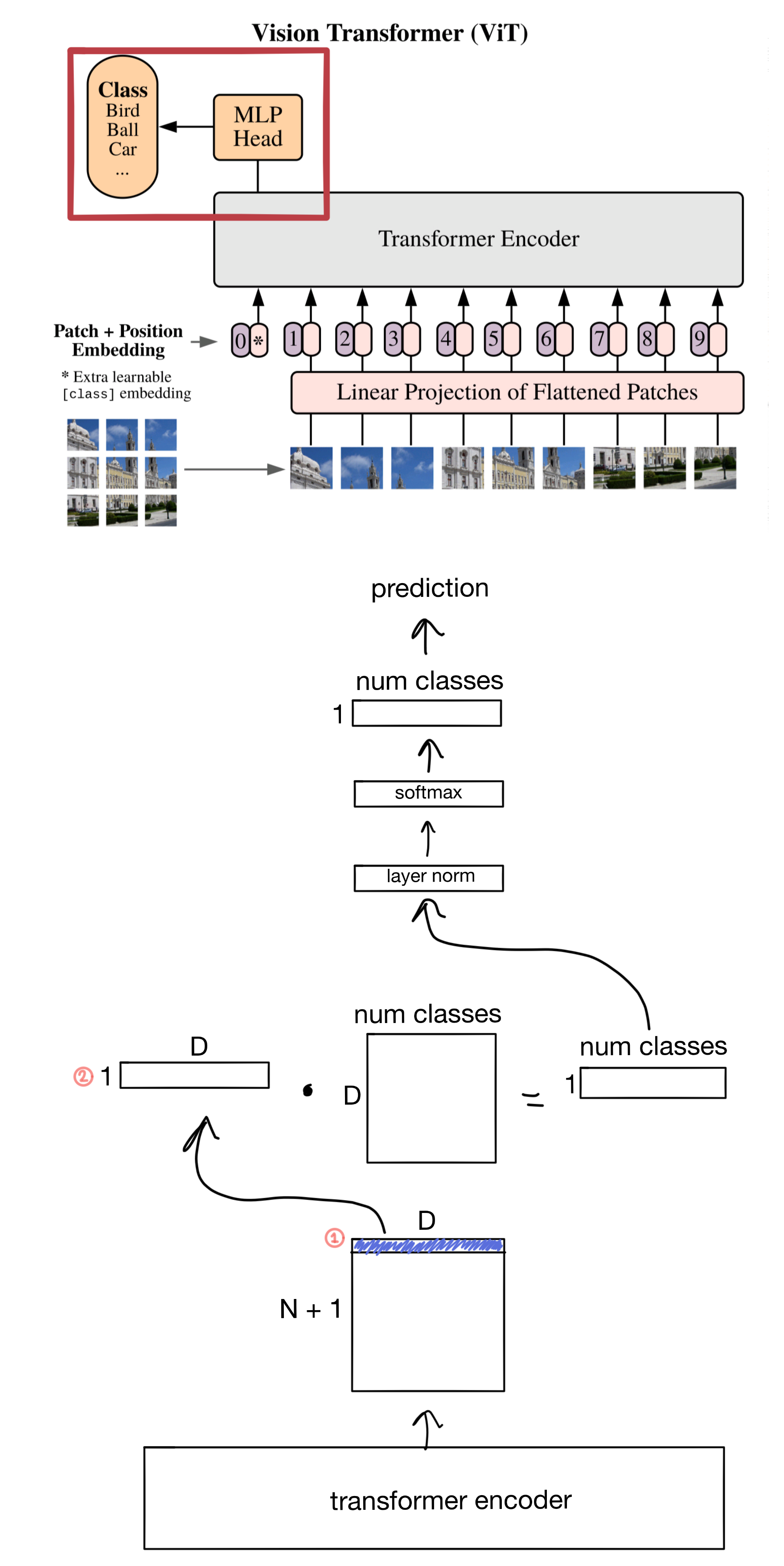
- The clf token is extracted from the encoder output.
- Just making another note here that I'm ignoring the batch dimension. In actuality this would be a matrix of shape B x D where B is the batch size.
1. ViT: https://arxiv.org/abs/2010.11929
2. Transformer: https://arxiv.org/abs/1706.03762
3. BERT: https://arxiv.org/abs/1810.04805v2