Prov-GigaPath: A whole-slide foundation model for digital pathology from real-world data - A Paper Walkthrough
Deep learning with whole-slide images (WSIs) is difficult: each WSI contains tens of thousands of image tiles.


Deep learning with whole-slide images (WSIs) is difficult: each WSI contains tens of thousands of image tiles. Traditional models typically sample a subset of these tiles and/or require manual labeling of images. Because of these shortcomings, they A) miss global context and B) do not generalize well outside curated datasets. Prov-GigaPath from Microsoft tackles this by pretraining directly on 1.3B tiles from 171K slides representing a variety of tissue types and over 30K patients. A foundation model that can learn from this full context (both local and global) of all these slides would allow better generalization to downstream classification tasks that are clinically relavent such as mutation prediction, sub-typing, etc.
Lets get into it!
Whole Slide Image (WSI) preprocessing
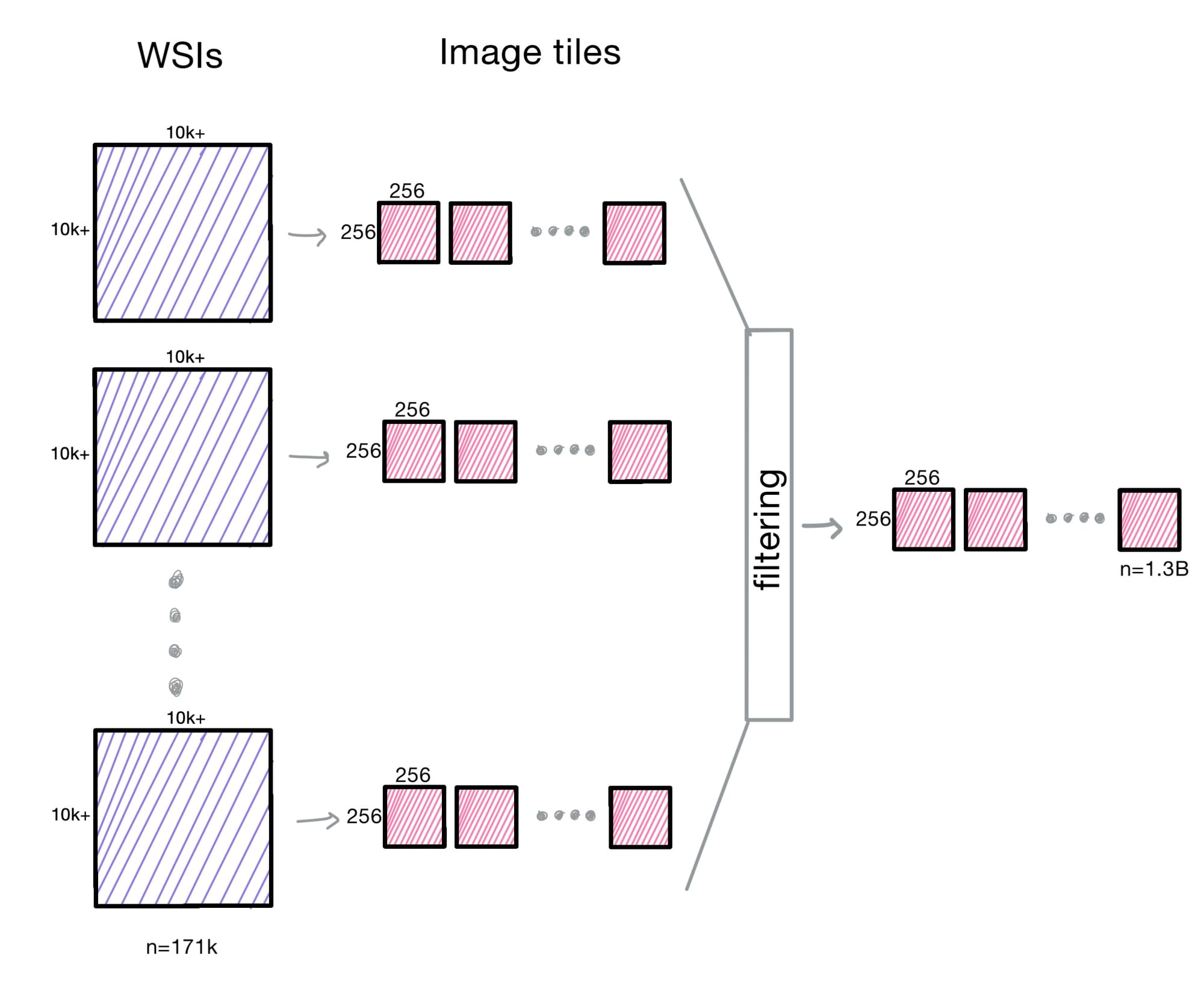
Prov-GigaPath begins with 171,189 H&E and IHC-stained WSIs collected from the Providence healthcare system.
These WSIs are then shredded into 1.38 billion 256×256-pixel tiles, with each treated as a visual token. They then filter tiles with less than 10% tissue coverage. All slides are also resized to the same resolution. This preprocessing took 157 hours over a 200 node cluster, each with 32CPUs!
Prov-GigaPath uses a two-stage pretraining strategy:
- Tile-level pretraining with DINOv2
- Slide-level pretraining with a Masked Autoencoder implementing LongNet
Tile-level pretraining with DINOv2
If things aren't making sense, and if you haven't already, check out my DINO and DINOv2 posts for more background.
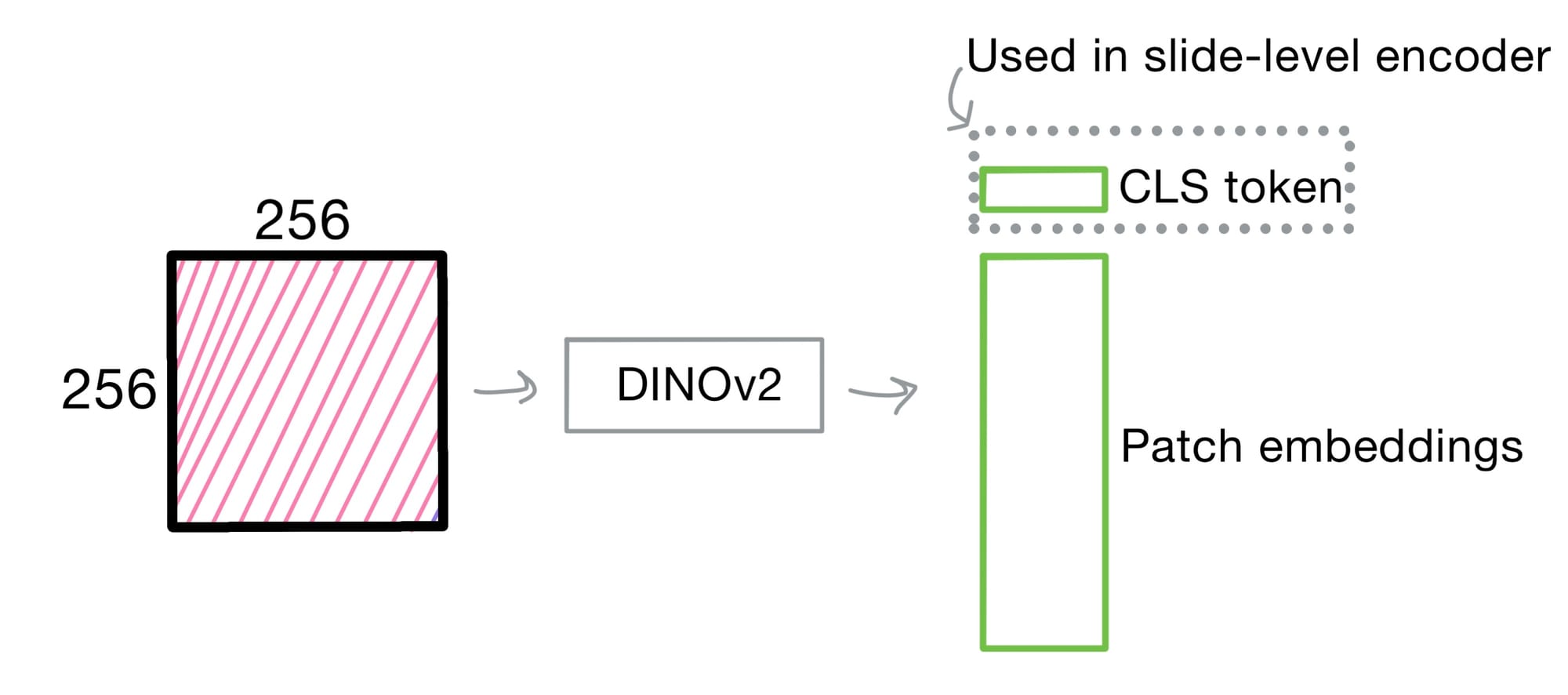
DINOv2 trains the tile encoder by applying contrastive learning between global and local crops from each 256×256 tile. This is crucial in pathology, where semantic meaning across magnifications and stains is hugely important. DINOv2 ultimately supplies Prov-GigaPath with rich tile-level embeddings for IHC and H&E tiles.
Here we consider two tile crops (or views) for our high-level visual explanation.
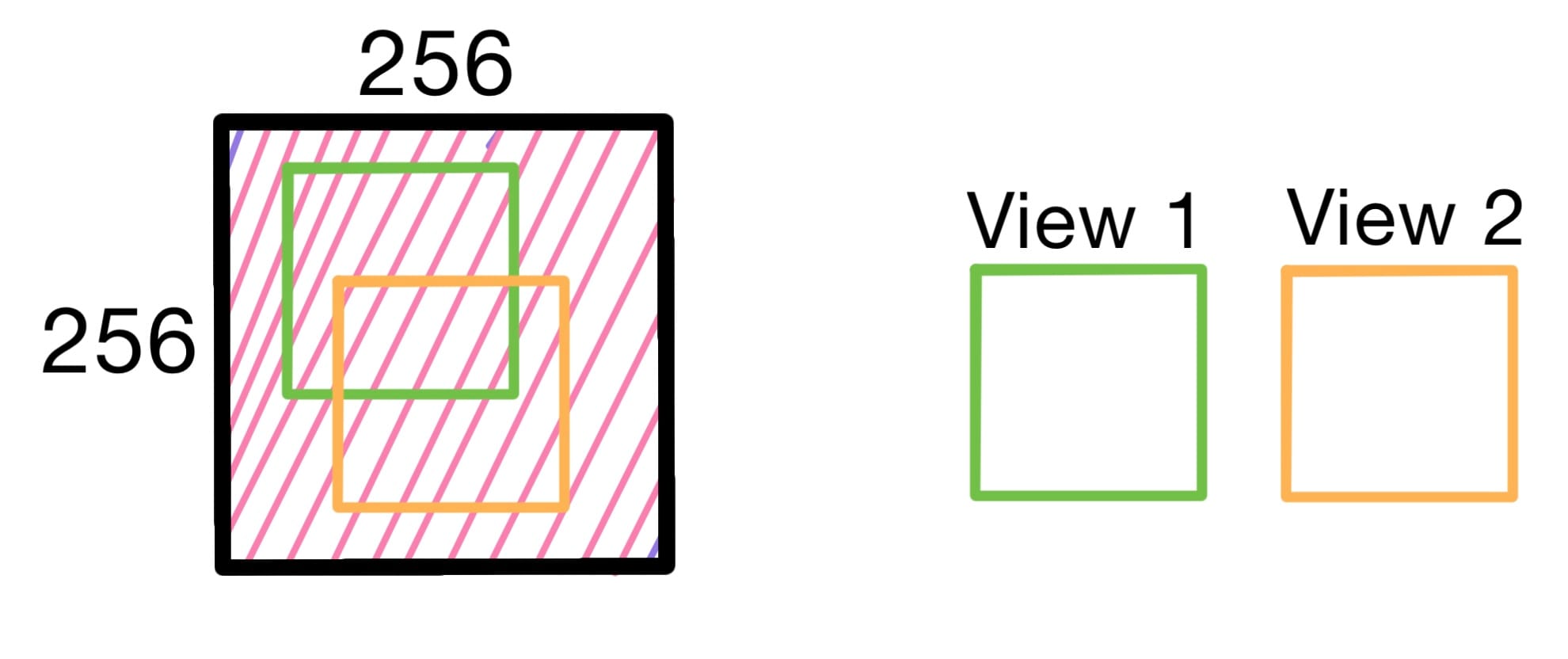
Note: DINOv2 takes more than just two views. It takes two global views and 2+ local views. For more details on global vs. local views and which views are involved in which loss function check out my original DINO and DINOv2 posts.
Classification Loss in DINOv2
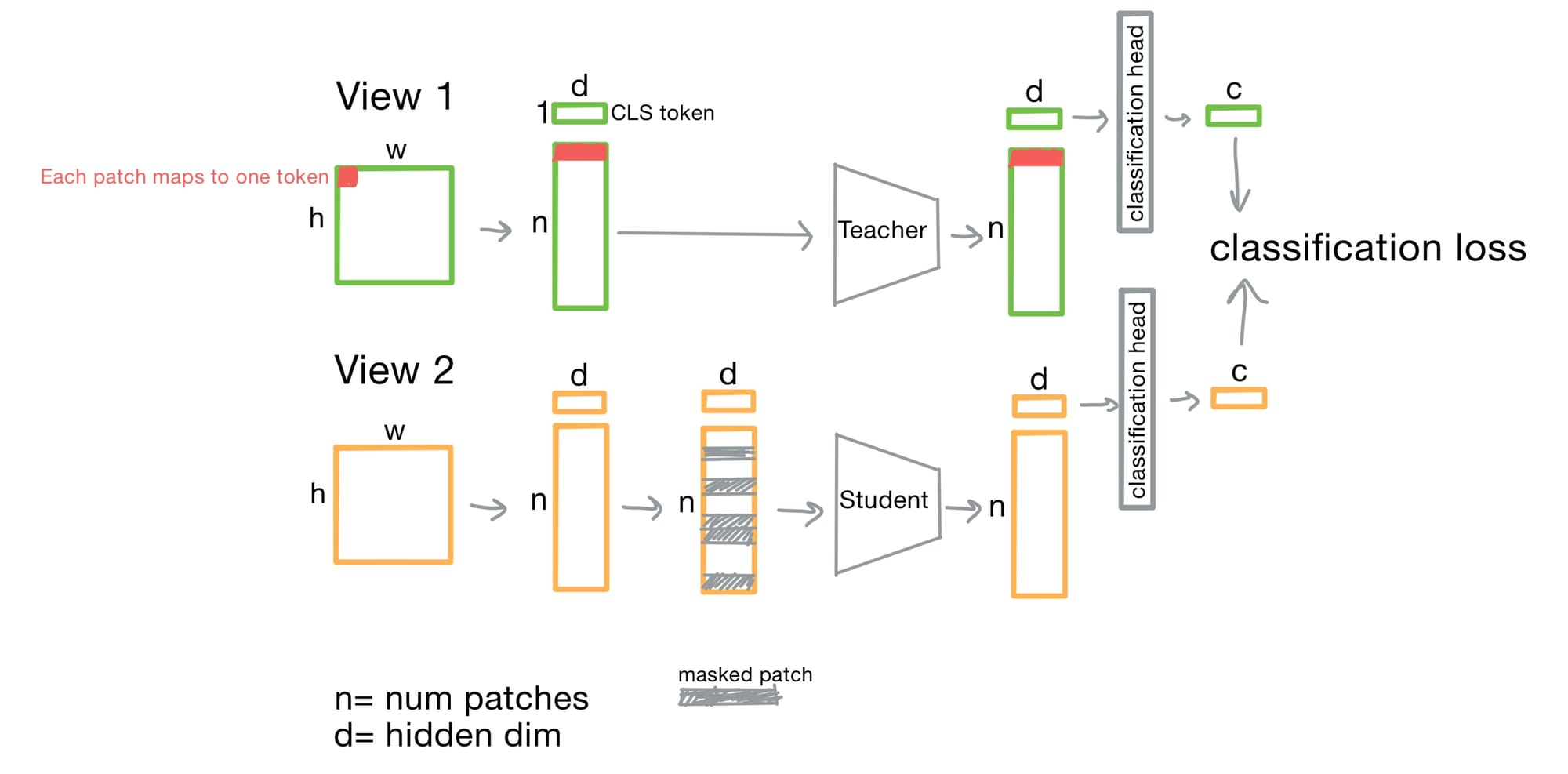
The classification loss pushes the CLS token of each view to be similar, as they share the same global tile, and dissimilar otherwise. Eventually, this CLS token carries an embedding that contains enough information to well discriminate these views.
iBOT Patch-Level Loss in DINOv2
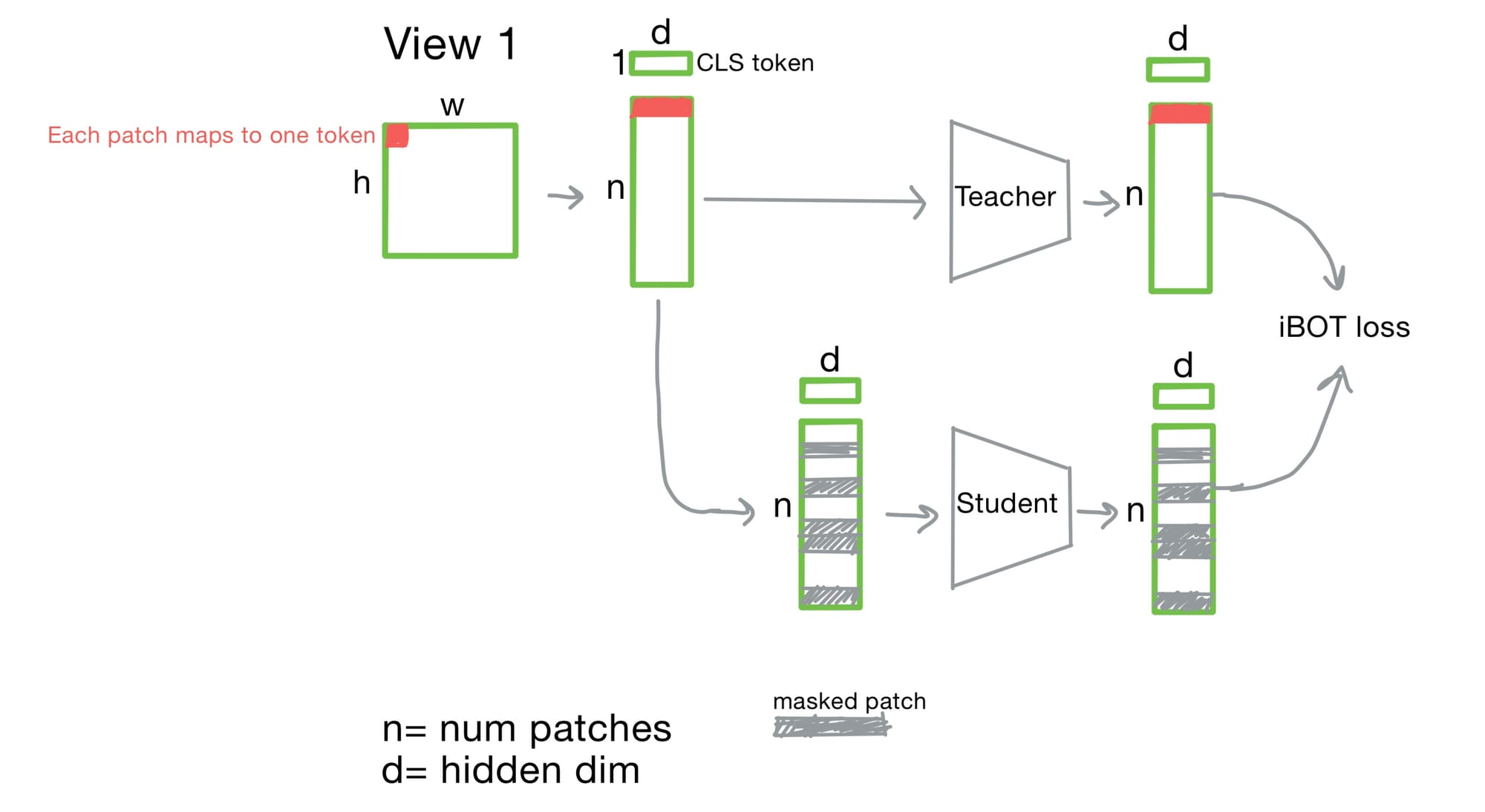
The iBOT loss compares masked patch embeddings between teacher and student models, forcing the model to recover spatial structure. This is critical in pathology, where high resolution local features may encode diagnostic cues.
Why the CLS Token Matters
After DINOv2 training, the CLS token contains an information rich, compressed representation of the tile that (hopefully if training went well) captures both content and spatial context. These tile-level CLS tokens become the input sequence to the slide-level encoder, enabling Prov-GigaPath a scalable way to move from local to global modeling.
Slide-Level Pretraining with LongNet and Masked Autoencoder
Slide-level modeling matters because diagnoses usually depend on how visual patterns are contextualized across an entire whole slide.
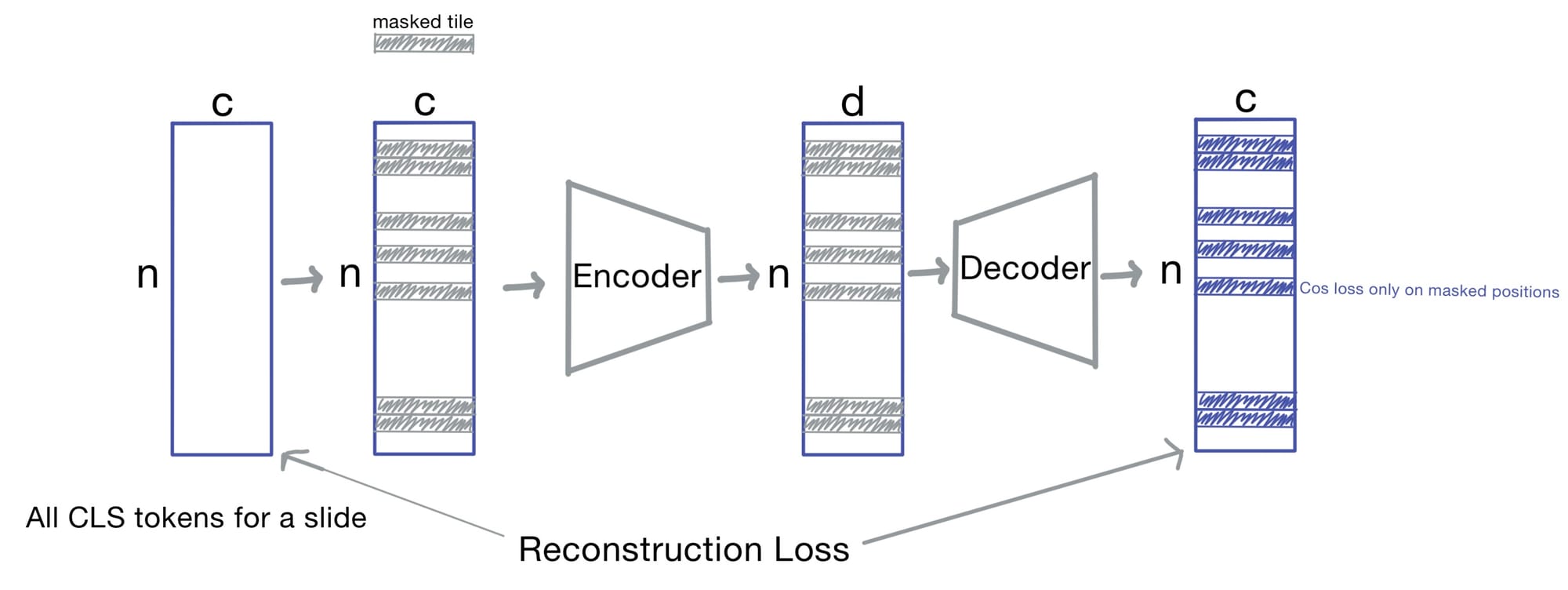
Prov-GigaPath uses a masked autoencoder (MAE) on top of LongNet, a transformer designed for long sequences (capable of handling a theoretical limit of billions of tokens).
The Masked Autoencoder
The masked autoencoder drops 75% of tile embeddings during training and asks the model to do the following task: reconstruct the tile embeddings based on the remaining tiles. Additionally, slides are augmented through tile reordering, cropping, flipping, and noise injection. Image tiles
Dilated Attention
Regular self-attention is quadratic in sequence length—making it impractical for WSIs, where tiling results in tens of thousands of tiles. LongNet addresses this with dilated attention. For more on this, check out my LongNet post, but this jist is the following:
- It splits the tokens into segments
- Within each segment, it samples tokens at fixed intervals (e.g., every 2nd or 4th tile)
- Then it computes attention among these sparse subsets
This gives the attention computation O(N) complexity instead of O(N²), making it possible to model entire slides.
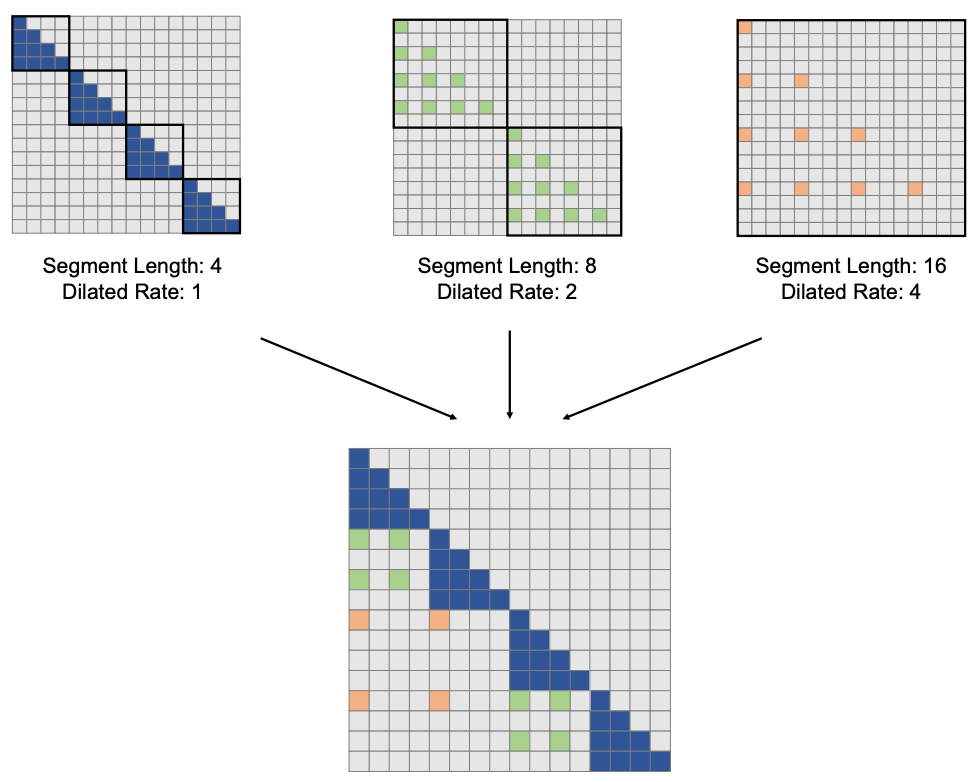
Above is a visual representation of dilated attention from the LongNet paper, where you can see where a colored tile (represented as rows/columns) only attends to other colored tiles, making the attention computation tractable.
Application to Downstream Tasks
Now that we have a trained model, what can we actual do with it?
Prov-GigaPath was tested on a diverse benchmark of 26 pathology tasks, including:
- Cancer subtyping for 9 tumor types
- Mutation prediction
- Tumor mutation burden (TMB) classification
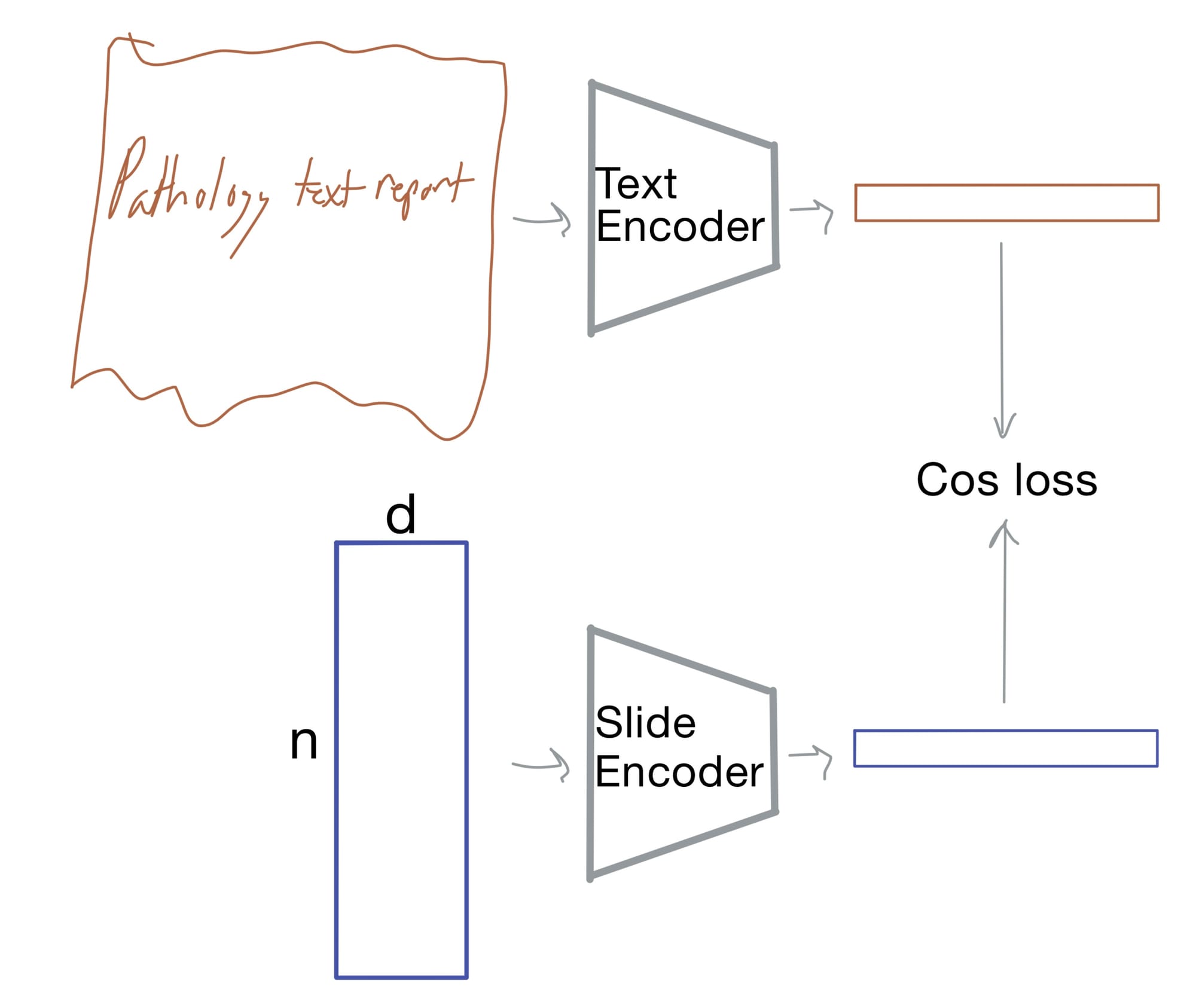
For example, Prov-GigaPath was further trained with OpenCLIP on 17K slide–report pairs. Using contrastive loss, it learned to align slide embeddings with pathology report text. Then, once aligned, a text prompt like "Lung adenocarcinoma" can retrieve or classify slides without needing labeled training examples.
Below I illustrate a toy example of OpenClip, and how it could be used to align text and image embeddings, a crucial step in zero shot classification that is used in the publication.
Conclusion
In short, the two-stage DINOv2 + LongNet pretraining approach allows Prov-GigaPath to learn local and global spatial patterns, enabling a variety of downstream tasks useful for WSI-based diagnostics.
Foundation models (like Prov-GigaPath) are crucial because they are so flexible, making them indespensible to the scientific community. And since the weights are open sourced, anybody can spin up a model from them.
This post was part of a three post series, check out the others!