DINOv2: Explained
DINOv2 is a continuation of the original DINO framework published by Meta in 2021. It improves self-supervised visual learning by producing more semantically meaningful patch-level features—without the need for labeled training data.


DINOv2 is a continuation of the original DINO framework published by Meta in 2021. It improves self-supervised visual learning by producing more semantically meaningful patch-level features—without the need for labeled training data.
I also wrote a previous article on the initial version of DINO, check it out here. I previously wrote about the first version of DINO, and I’d encourage you to start there if you’re unfamiliar with concepts like student/teacher models, distillation, or view augmentations.
DINOv2 builds on the original by making improvements to multiple areas:
Data curation
Meta curated a dataset of 1.2 billion images. But importantly, they applied deduplication and filtering steps to avoid domain bias and near-duplicate image contamination. After filtering and curation, they were left with an image dataset comprising 142M images.
Efficiency
DINOv2 allows efficiency improvements that parallelize it easily across GPUs. Additionally, they implement a new version of flash attention to speed up training.
Regularization
DINOv2 uses KoLeo regularization—a technique that encourages uniform distribution of patch embeddings on the hypersphere. Ultimately this helps prevent feature collapse and forces better coverage of the patch feature space, resulting in more semantically meaningful patches.
Loss
But the most substantial improvement is the addition of a new patch-level loss, inspired by iBOT—another self-supervised learning method. This patch-level loss allows DINOv2 to learn semantically meaningful representations not just at the image level, but at the patch level.

But before we get into iBOT, lets quickly recap the loss function from the original DINO paper.
A Quick Recap: DINO’s Original Loss
The core idea behind DINO’s loss is view consistency, meaning different augmentations of the same image should produce similar embeddings. A teacher model generates targets, while a student model learns to match those outputs via cross-entropy on the CLS token.
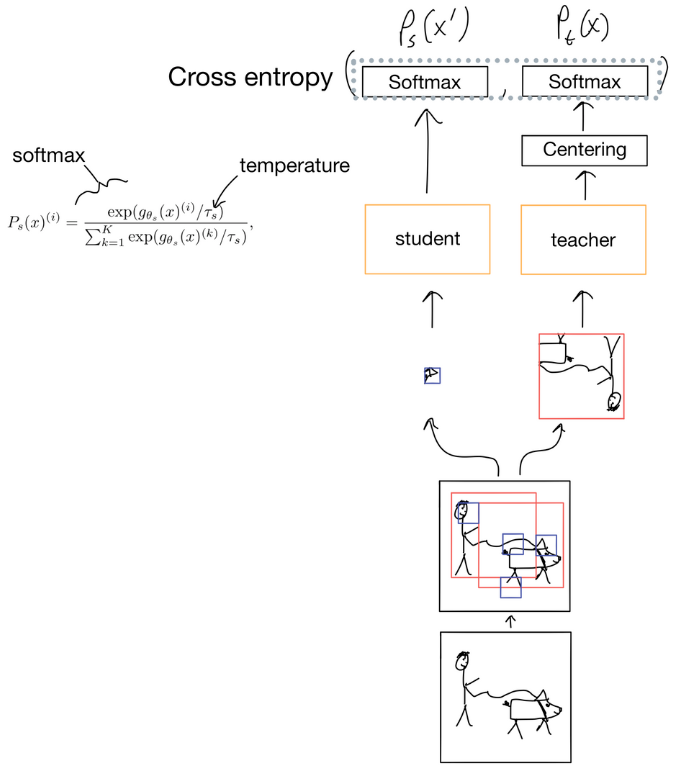
This encourages global image-level alignment without needing labels, and it works remarkably well with vision transformers (ViTs).
The Patch-Level Objective from iBOT
DINOv2 incorporates iBOT's patch-level loss to go beyond global image-level alignment. The key idea is to match patch embeddings between teacher and student encoded views, even when parts of the image are masked.
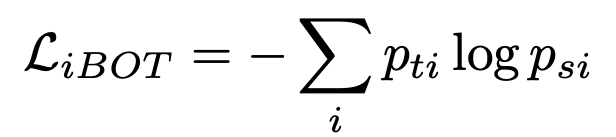
Below is a basic depiction of iBOT loss in action.
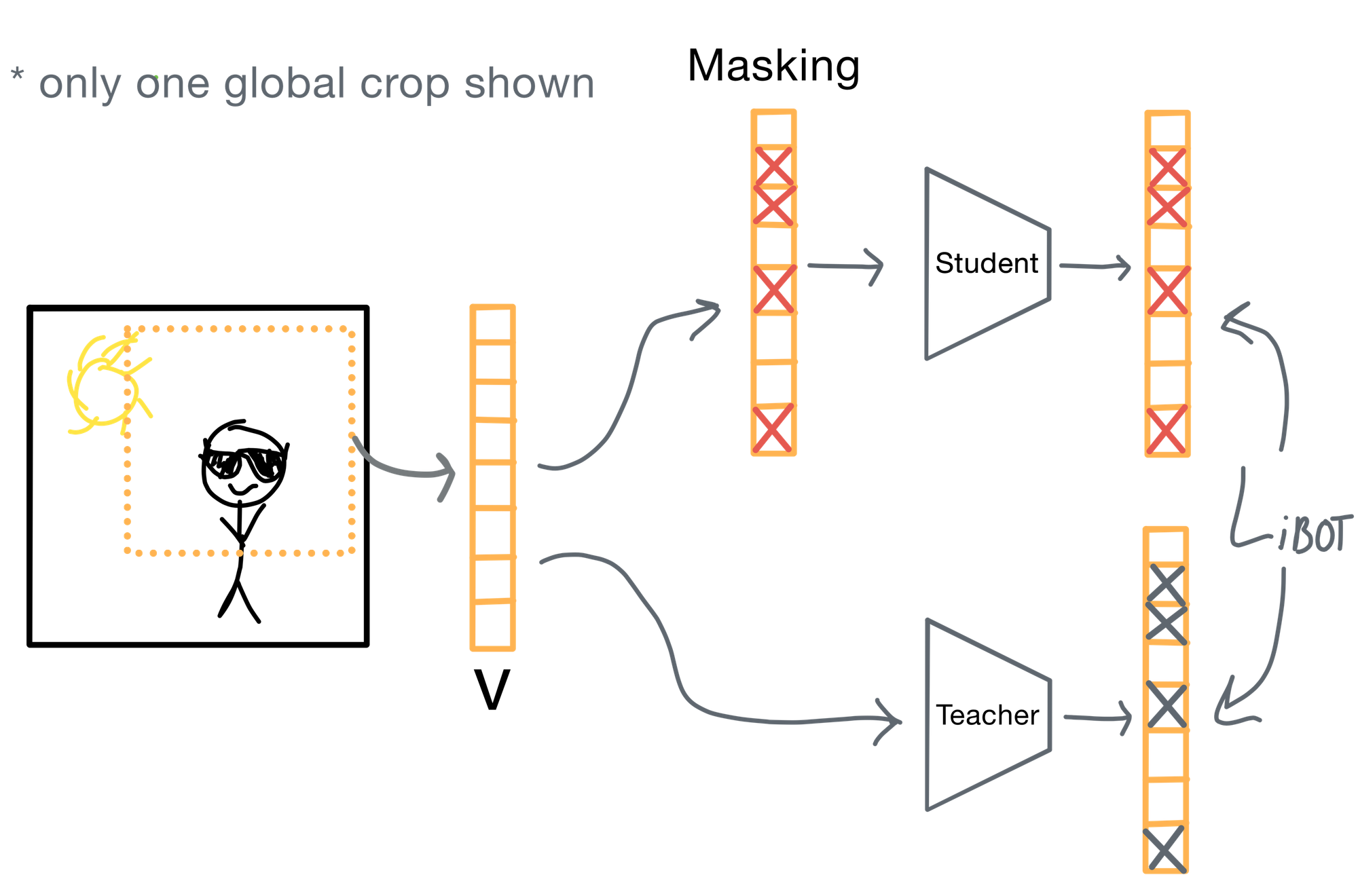
A brief breakdown of how the iBOT loss works:
- Two different views of an image are created: one for the student, one for the teacher.
- A random subset of patches in the student input are masked, while the teacher sees the full view. This is a technique commonly used in masked autoencoders.
- The teacher produces patch-level embeddings for every visible patch. However, only the patches in locations that are unmasked in the student are used for calculating the loss.
- The student is trained to match the teacher’s outputs on the unmasked patches using cross-entropy over a softmax of patch logits.
This encourages the student to infer semantics from the views—important for tasks like segmentation or retrieval. Ultimately this is why DINOv2 is so useful as a pre-training step in front of other models.
Summary
With no labels, DINOv2 pre-training allows strong performance across classification, segmentation, and depth estimation tasks. Much of this performance increase over V1 is due to a reformulation of the loss (from iBOT), that forces more semantically meaningful patch embeddings.
Speaking of pre-training, this post is part one of a three part series that covers foundation models in image pathology. Check out the others here:
- DINOv2 [This post!]
- LongNet [coming soon]
- GigaPath [coming soon]