Segment Anything: Explained
Segment Anything (SAM) proposes a flexible foundation model for image segmentation. It can respond to query points, boxes, masks, or text, and return masks corresponding to those prompts. Curcially, this design allows for zero or few-shot transfer learning to a wide variety of tasks.


Segment Anything (SAM) proposes a flexible foundation model for image segmentation. It can respond to query points, boxes, masks, or text, and return masks corresponding to those prompts. Curcially, this design allows for zero or few-shot transfer learning to a wide variety of tasks.
In this post, I’ll only be focusing on the mask decoder portion of the Segment Anything architecture. But to briefly describe the overall architecture, it is as follows:
- An image is passed through a masked autoencoder (MAE) with a vision transformer (ViT) backbone to produce an image embedding
- Prompt tokens (points, boxes, masks, or text) are encoded separately
- The mask decoder (what we'll be talking about), is a lightweight two-layer transformer that combines image and prompt information to generate segmentation masks
- SAM is trained using focal + dice losses between predicted and groundtruth masks.
- During training, simulated prompts are generated via a iterative segmentation loop
- During inference, SAM segments images from a variety of types of prompt tokens (points, boxes, masks, or text)
With that brief overview out of the way, let's get into the mask decoder
The Mask Decoder
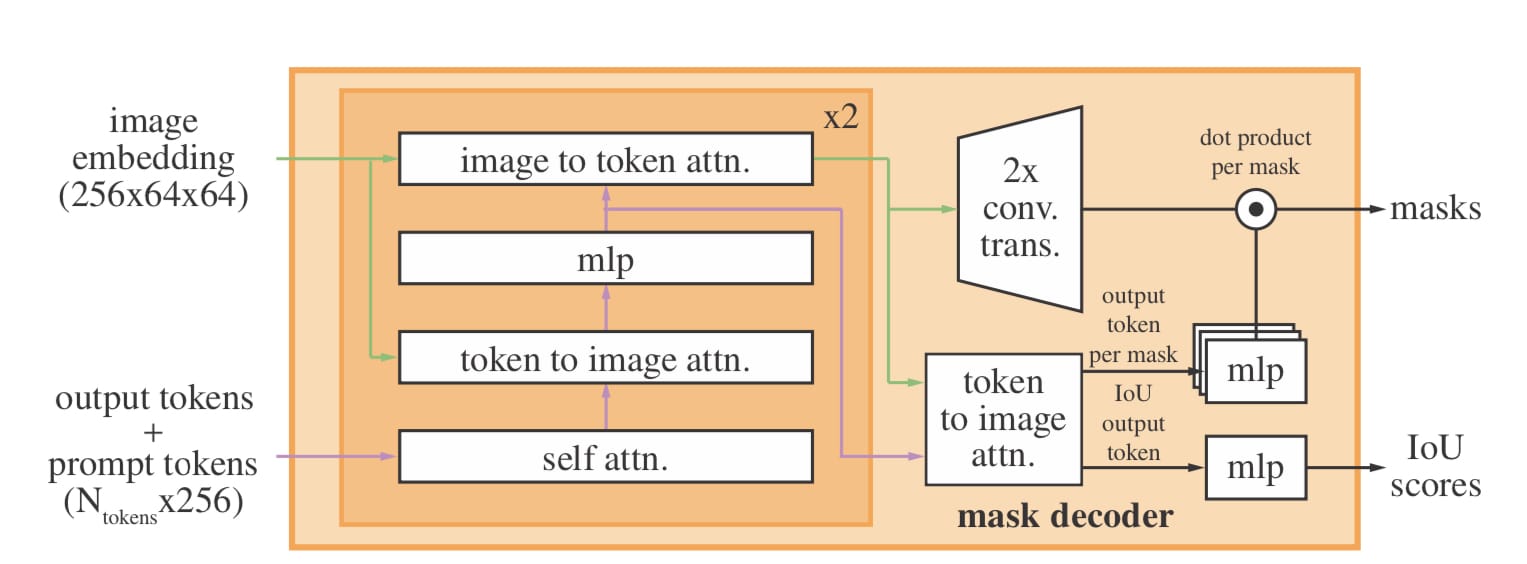
Inputs
There are two main inputs to the mask decoder: image embeddings and prompt tokens.
The image embeddings are computed once per image using the VIT image encoder. The result is a 64×64 grid of 256-dimensional features representing the visual content of the input image.
The prompt tokens are 256-dimensional vectors representing sparse or dense input (points, boxes, masks, or text). These are created using positional encodings and type embeddings for geometric prompts (points, boxes), and via a CLIP text encoder (text).
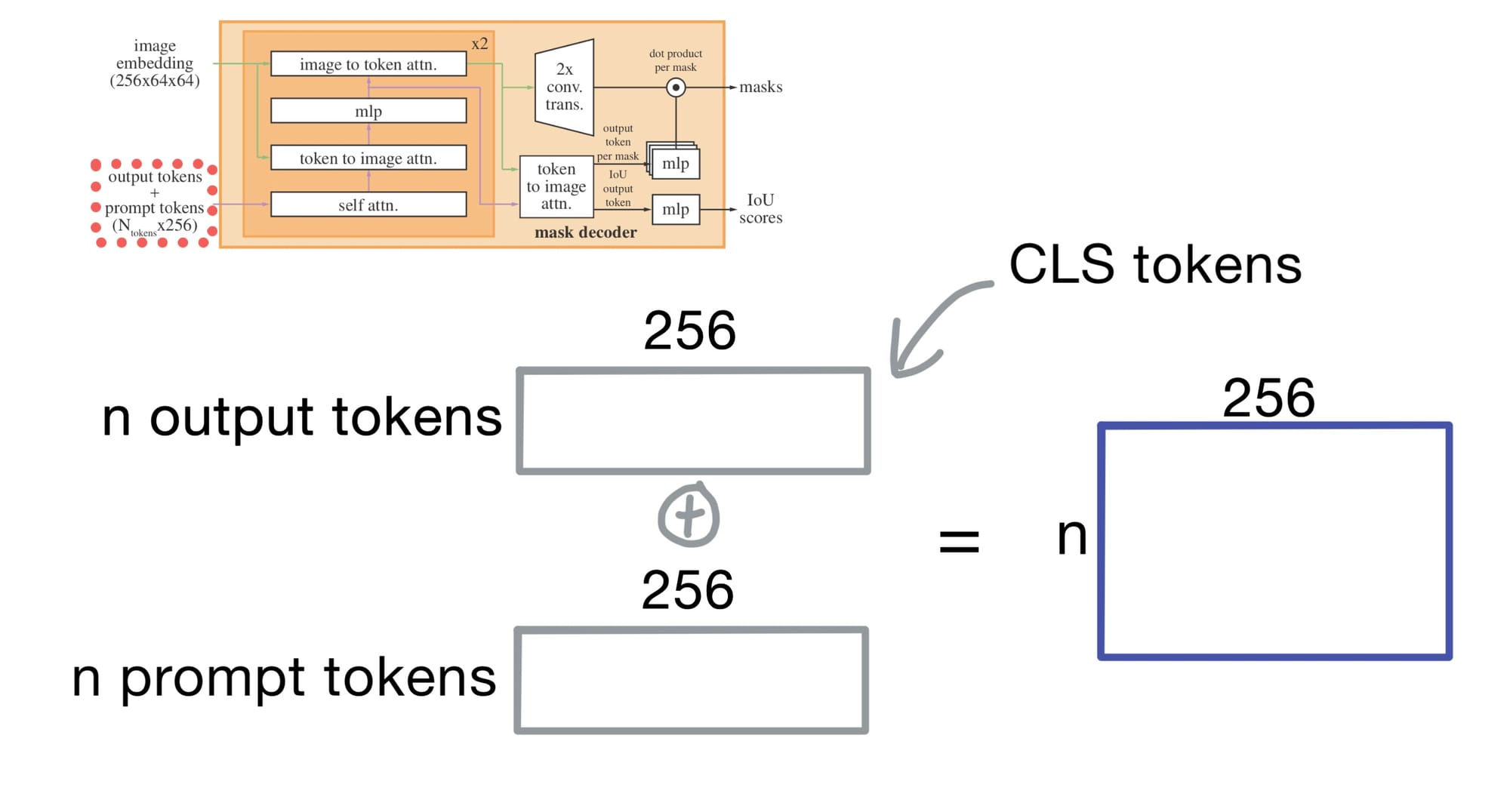
Output Tokens
The output tokens represent the query embeddings for the masks we're predicting. These tokens act like CLS tokens.
These output tokens are concatenated to the prompt tokens before entering the mask decoder. An additional output token is also added generate an IoU prediction for each mask (more on that later).
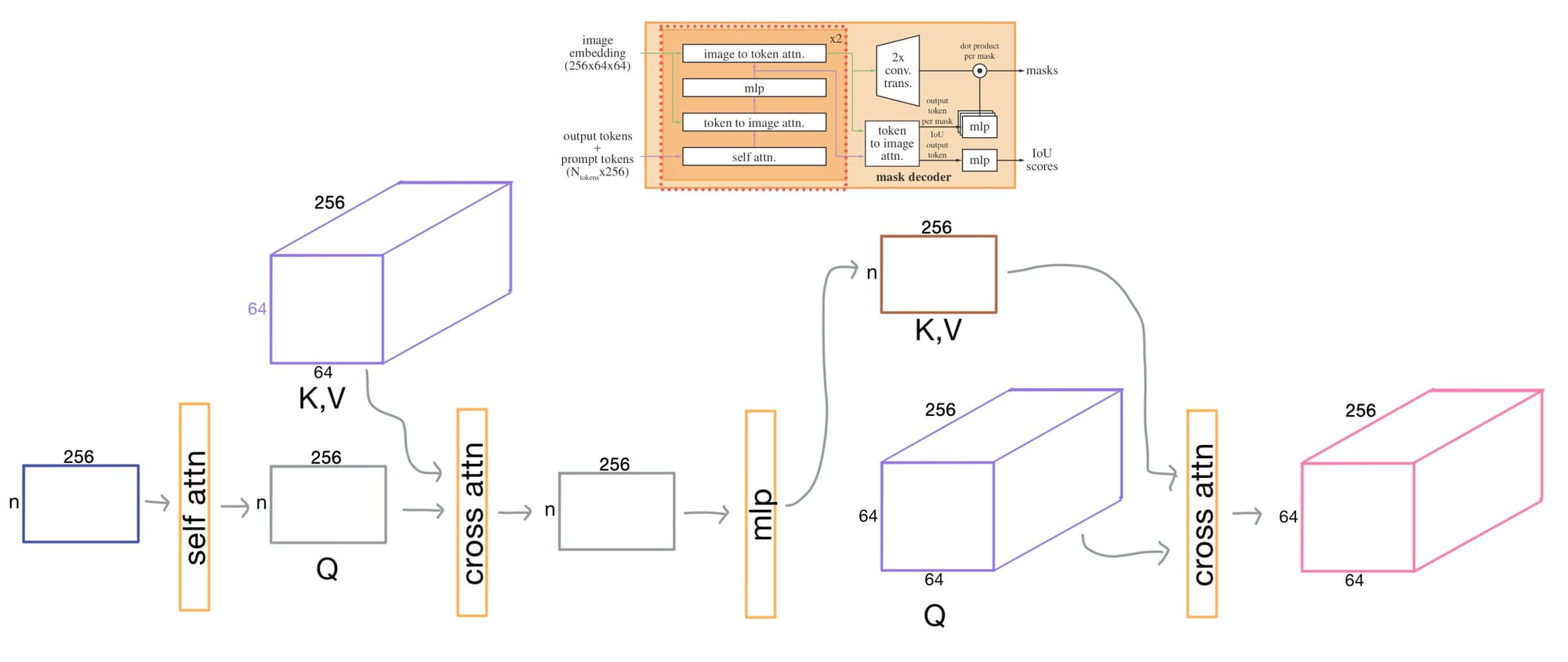
The Transformer Block
The transformer blocks main job is to mix and route information between the prompt/output tokens and the image embedding. Each layer consists of self-attention among prompt tokens, cross-attention from tokens to image features, and a reverse cross-attention from image tokens back to prompt tokens. This lets the prompt tokens update with image content, and the image tokens update with prompt context.
Final Attention and transposed convolutions
After the transformer layers, the activations are upsampled by 4× via two transposed convolution layers to bring it closer to the original image resolution.
Additionally, the output tokens again attend to the activations.
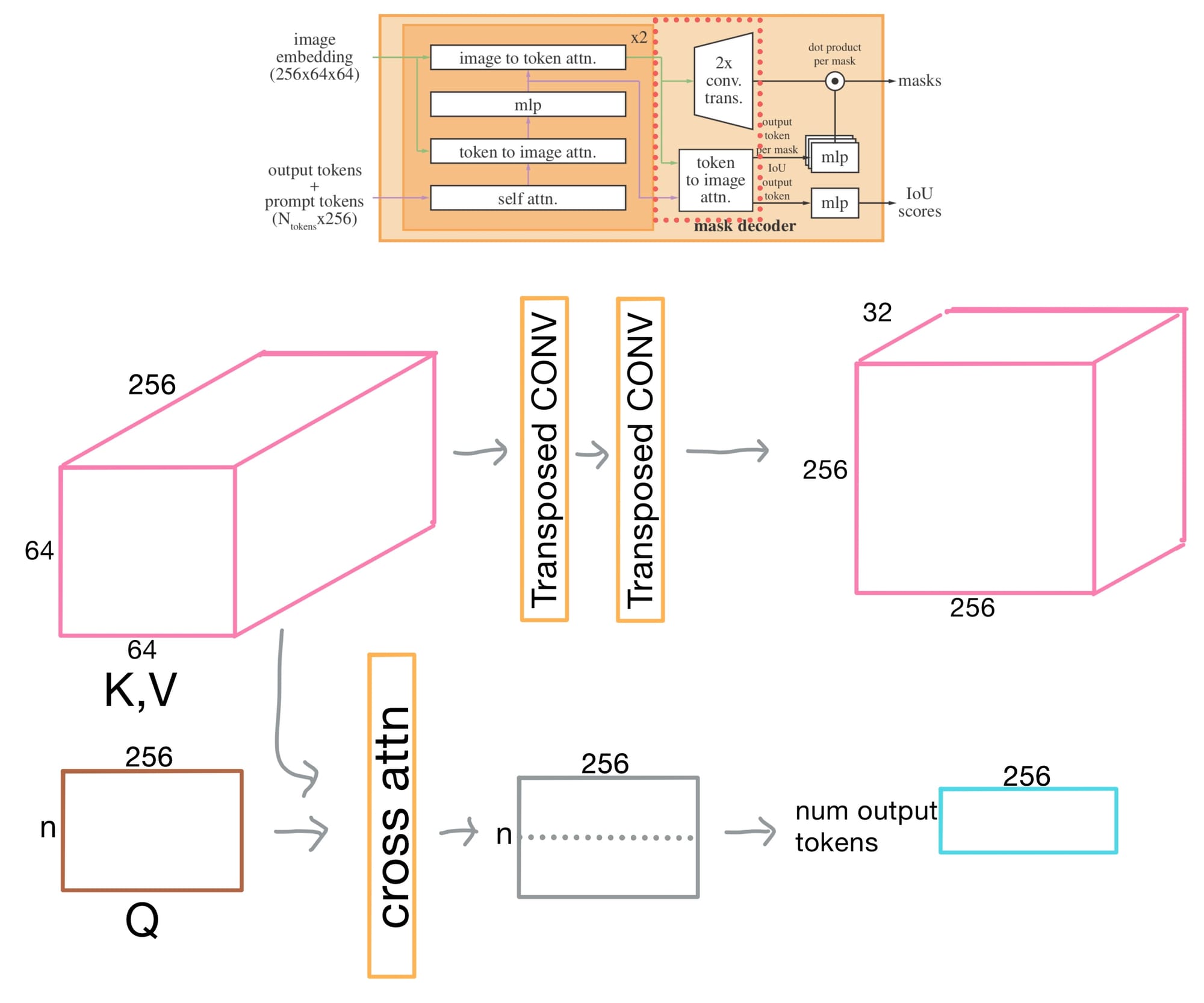
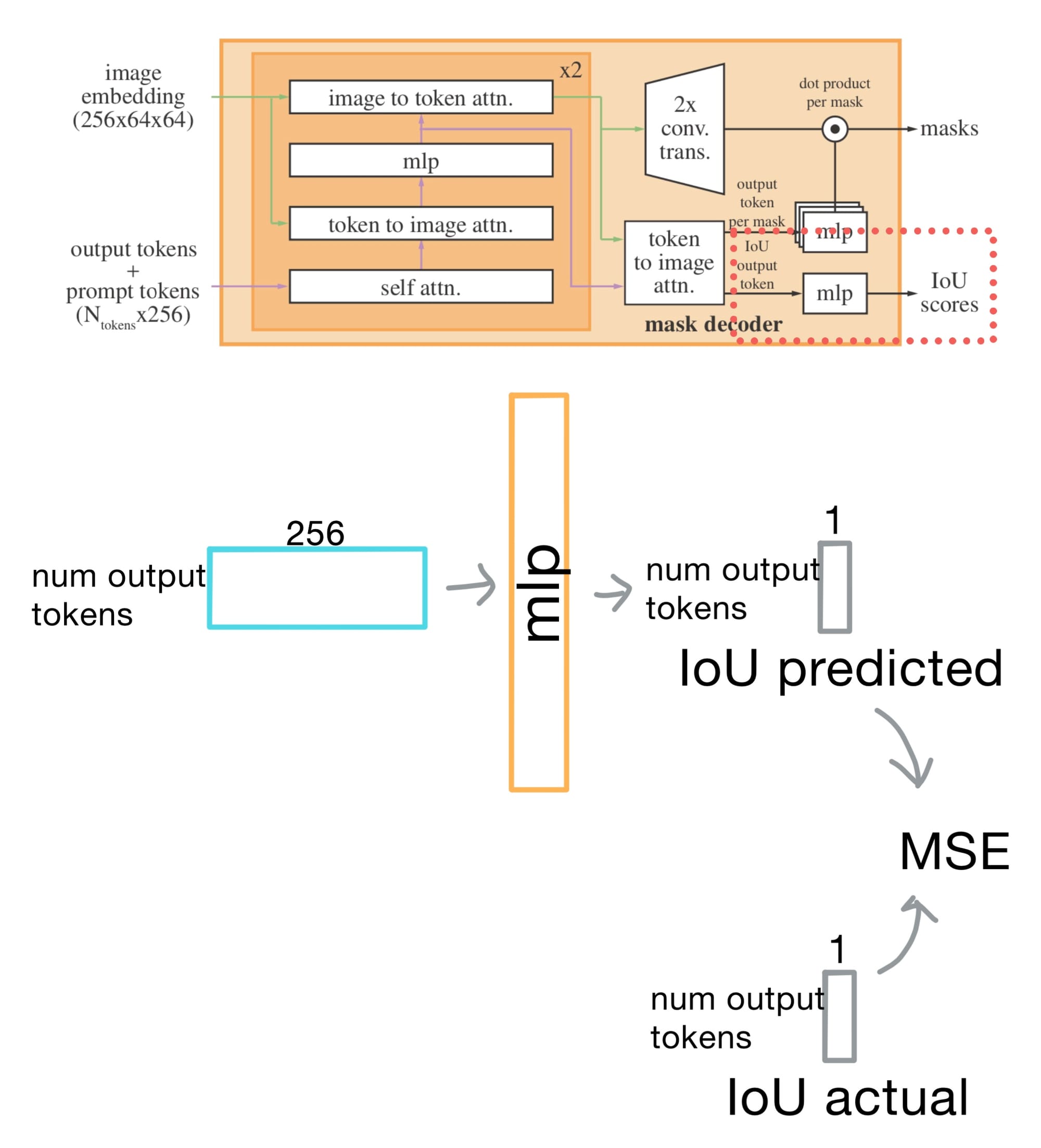
IoU prediction head
Briefly, before getting to the final mask prediction step, there is an intersection-over-union (IoU) head that predicts a confidence score for each mask. It does this by taking the mean-squared error (MSE) between the predicted mask and the ground truth. This is key for ranking multiple mask outputs, especially when there are ambiguous or overlapping possibilities.
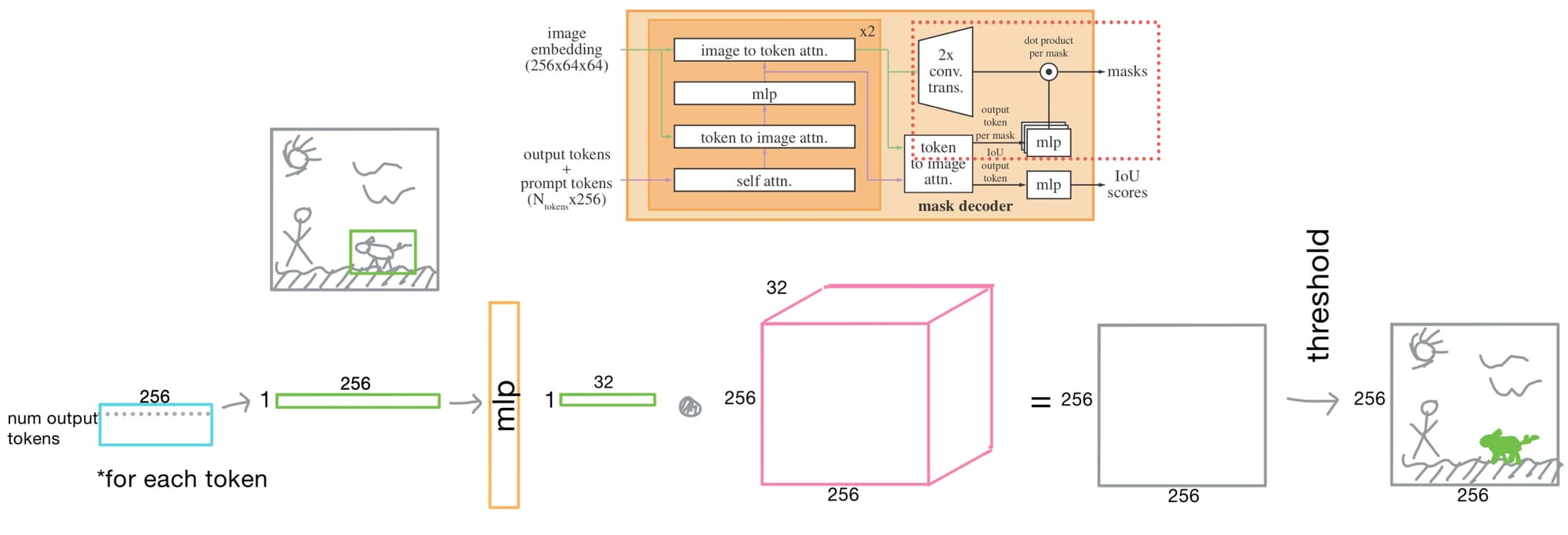
The Final Step: Mask Prediction
To generate the actual mask, every token is passed through an MLP. This vector is then dotted with the upsampled image embedding, producing a per-pixel mask logit map. The logits can then be thresholded to produce a final mask.
This mechanism is quite elegant!
That's all for todays post, cheers!