Paper Walkthrough: DeiT (Data-efficient image Transformer)
Walkthrough of the paper Training data-efficient image transformers and distillation through attention from Touvron et al. that introduces a new distillation for visual transformers.

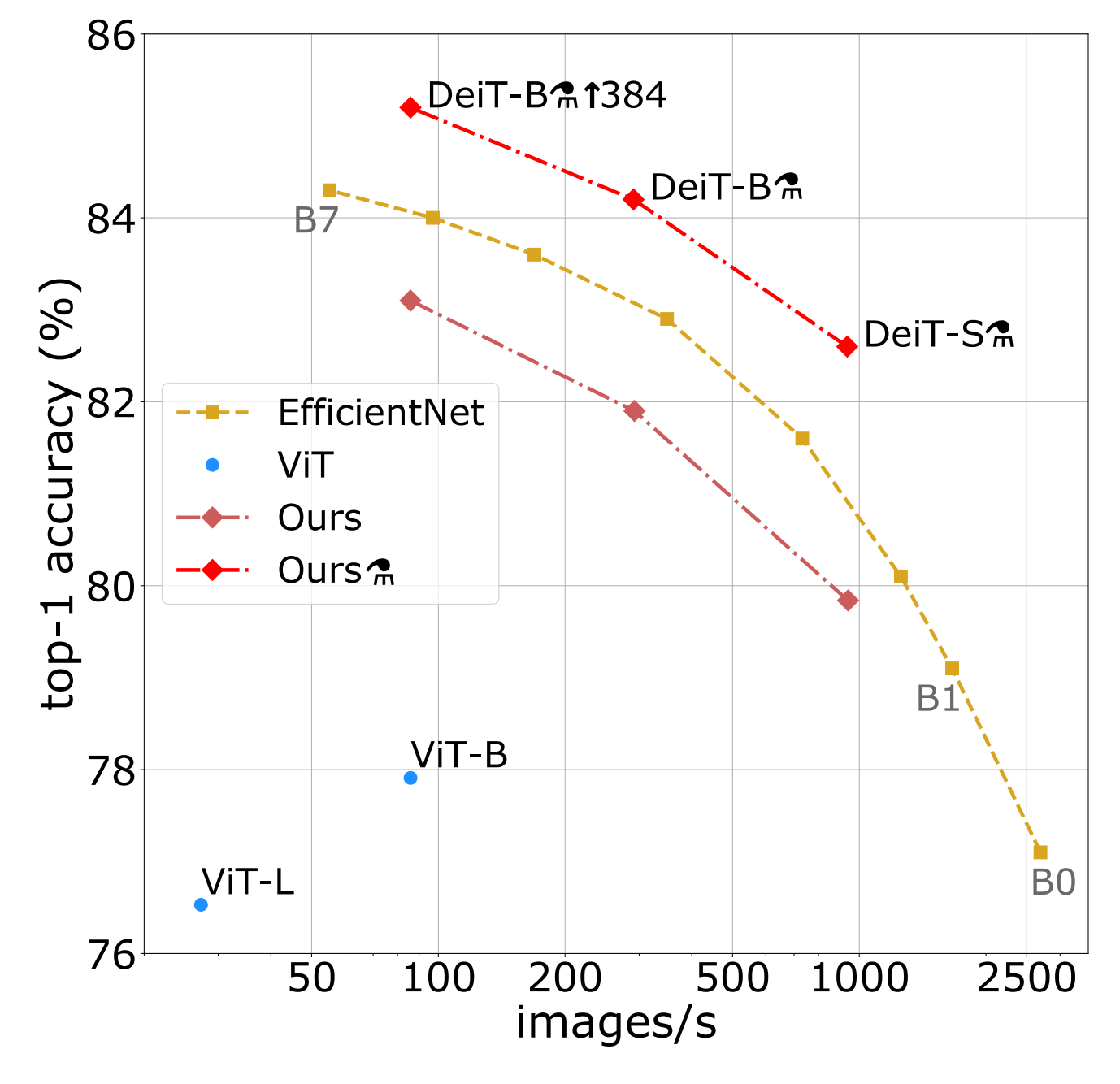
Walkthrough of the paper Training data-efficient image transformers and distillation through attention from Touvron et al. [1] that introduces a new distillation for visual transformers. The new training regime achieves SOTA results on ImageNet. Something DeiT's architectural predecessor ViT [2] only achieved on much larger datasets, making its adoption difficult for anything but extremely large datasets (>~10 million images).
Takeaways
- Convolutional layers are not necessary for SOTA performance on ImageNet.
- The main contribution of the paper is the introduction of a new distillation procedure that uses a distillation token. The distillation token is passed through the network in the same way the class token is passed through the transformer encoder, however its task is only to take part in the teacher/student distillation portion of the loss function. This allows for the class token and distillation token to take on the optimal characteristics for their respective tasks (teacher/student loss for the distillation token and student/groundtruth loss for the class token).
- Interestingly, the optimal choice for the teacher model is a convolutional network, rather than a transformer. The authors hypothesize this is due to inductive bias in the convolutional network that is especially suited for imaging-based tasks. So in other words the student gets the best of both worlds: the convnet's inductive bias from the teacher, and the benefits of attention from its own architecture.
- The results hold when DeiT is pre-trained on ImageNet and transferred to other datasets, indicating the model is suitable for transfer learning.
Walkthrough
Distillation
Distillation is a process in which a student model learns in part from another model (termed the teacher). Distillation can help with training in several ways, but typically the main two are: 1) implicit label smoothing that may be beneficial to training, and 2) mitigation of augmentation issues due to image cropping, etc. Additionally, in the case of this distillation set up if the teacher is a convnet the student may inherit some inductive biases beneficial to image classification.
The authors attack the distillation question from two angles. The first is whether to use soft distillation (the more traditional approach) or hard distillation (a new method they introduce).
Soft vs. Hard distillation

As we seen by the function above, the soft distillation loss function has two main parts: one that compares the softmax of the student logits to groundtruth, and another that compares the distribution of the student logits to teacher logits (both after softmax). There are also a few parameters adjusting how to weight each end of the loss function and the temperature of the distributions.

Hard-label distillation also has two main parts: one for comparison to groundtruth and one to the teacher. However instead of softly comparing the student and teacher softmax distributions, they instead convert the teacher output to a hard label and compare using cross entropy. This also has the benefit of not needing the gamma or temperature parameters that are present in soft distillation.
Ultimately the paper found that hard-label distillation was superior to soft distillation.
Distillation token
The second angle is the addition of the distillation token. The distillation token is what is used in the teacher/student portion of the hard-label distillation loss function (the class token is used for the student/groundtruth portion). The theory is that the distillation token will learn characteristics optimal for its portion of the loss, while the class token will learn characteristics optimal for its respective portion. This would not be possible if both student/groundtruth and teacher/student portions of the loss function used the same token. In fact, the authors quantify the difference between the distillation and class tokens and find that although they are very similar, they still have meaningful differences. Indicating that the distillation token is carrying different information than the class token.
The distillation token is input into the transformer encoder in the same manner as the class token. If you would like to see more about how the class token operates see my previous post on ViT. I also show the tensor operations involved below.
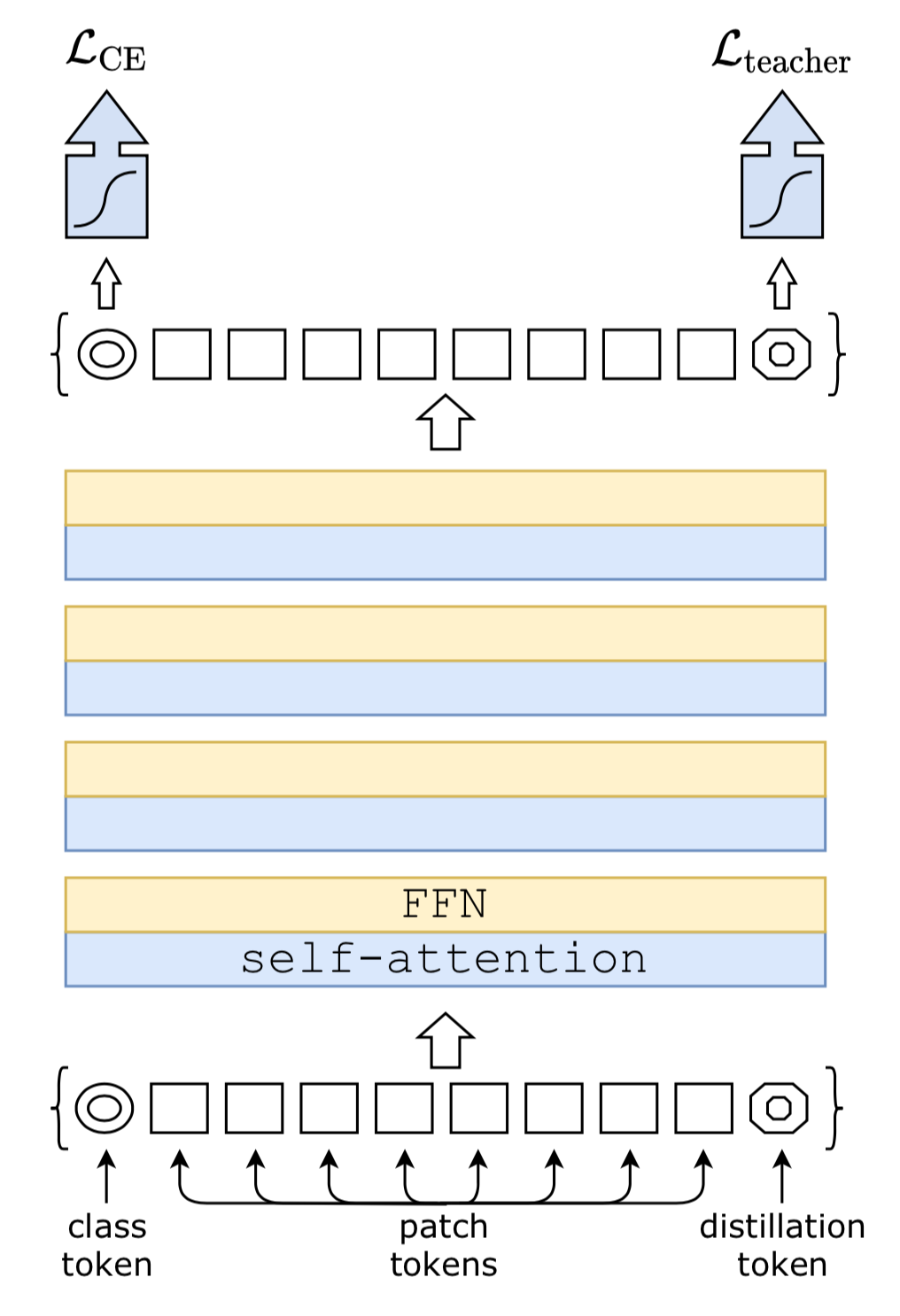
Below is a depiction of the tensor operations prior to input into the transformer encoder. (adapted from my post on ViT)
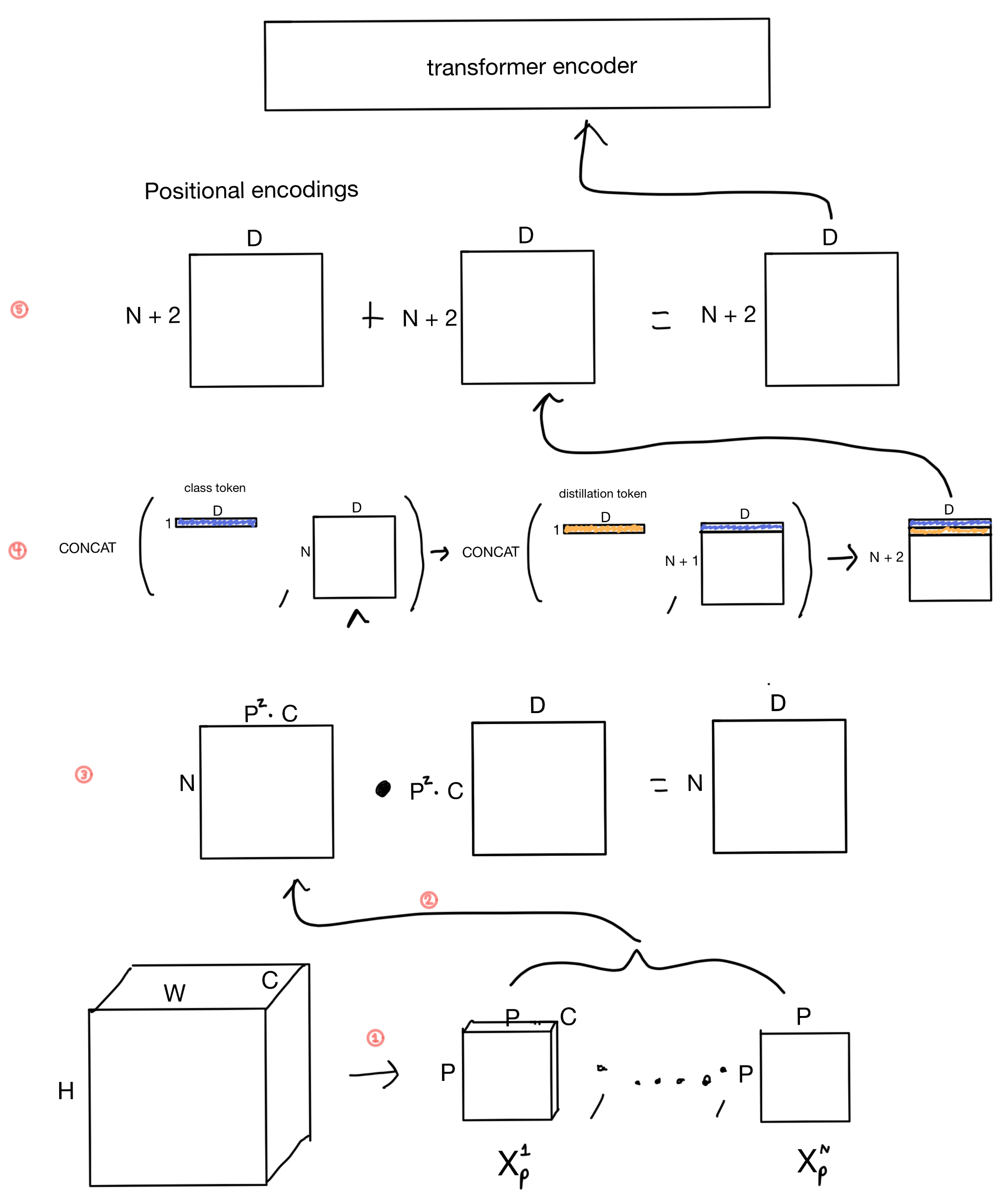
- The image of size H x W x C is unrolled into patches of size P x P x C. The number of patches is equal to H/P * W/P. For instance if the patch size is 16 and the image was 256 x 256 then there would be 16 * 16 = 256 patches.
- The pixels in each patch are flattened into one dimension.
- The patches are projected via a linear layer that outputs a latent vector of size D.
- The clf token and distillation token are added the patch sequence. They are learnable embeddings of size D that will ultimately be used for the global hard distillation loss function after they are fed through the transformer.
- Positional encodings are then added to the patches. The positional embeddings are learnable embeddings (rather than sinusoidal, like those used in the original Transformer architecture).
Here I visualize the global hard distillation loss function.
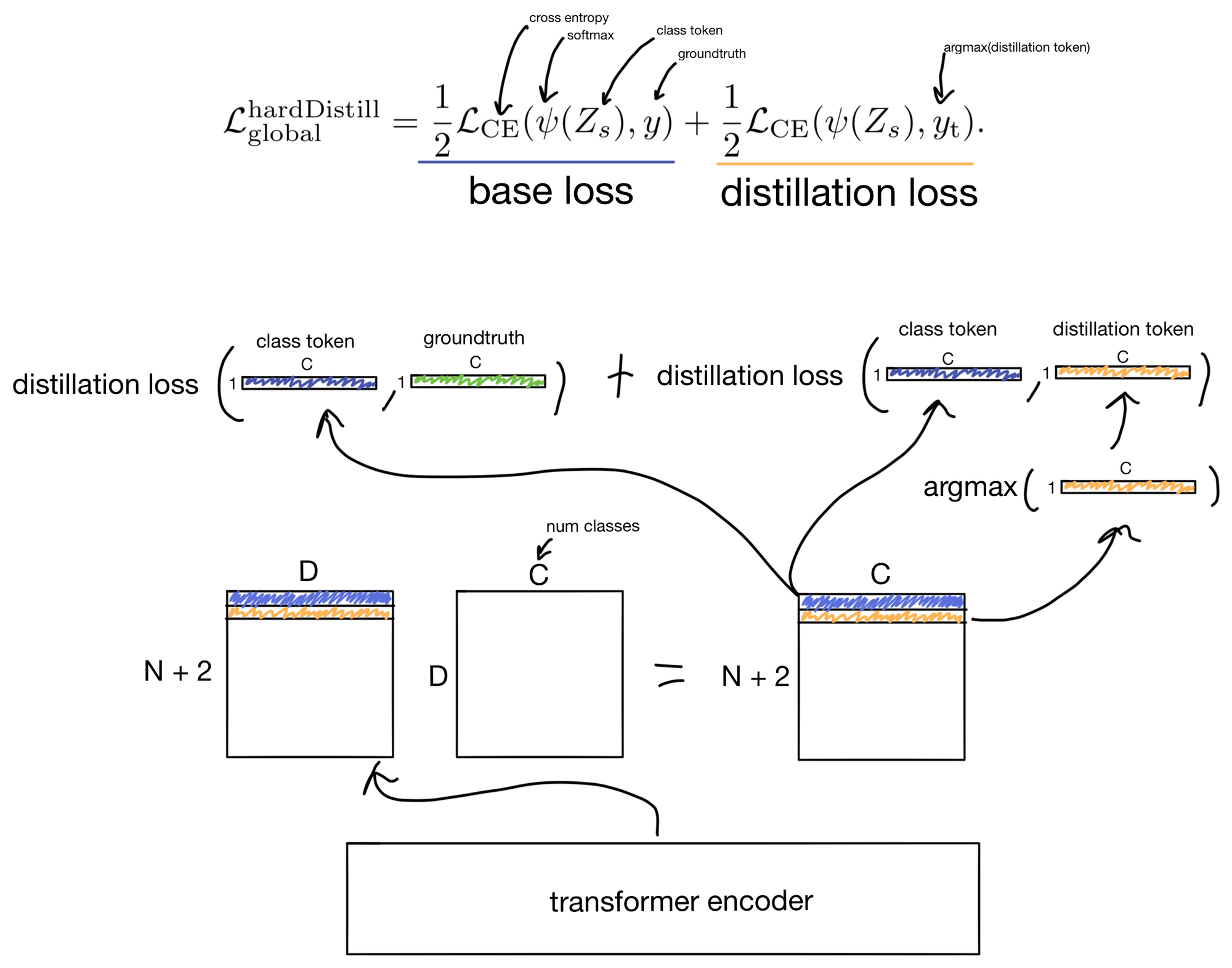
Note that this loss only applies during student model training. During inference time to make classifications the distillation and class tokens are added together, the resulting tensor is then used to make the class prediction.
Hope you enjoyed the post. Cheers :).
1. DeiT: https://arxiv.org/abs/2012.12877
2. ViT: https://arxiv.org/abs/2010.11929