Explained: Attention Visualization with Attention Rollout
In today's post I cover a simple method for visualization of attention in Transformers.

Transformers have become nearly ubiquitous for a number of computer vision and natural language processing tasks. In general, a large part of the Transformer's success is due to the self-attention mechanism. In self-attention, information is combined and mixed between tokens of the input sequence in each layer of the Transformer encoder. In deeper layers of the model however, the information tends to become increasingly mixed. This presents a problem: for deeper layers, attention weights don't produce explanations that are as reliable as earlier layers in the network.
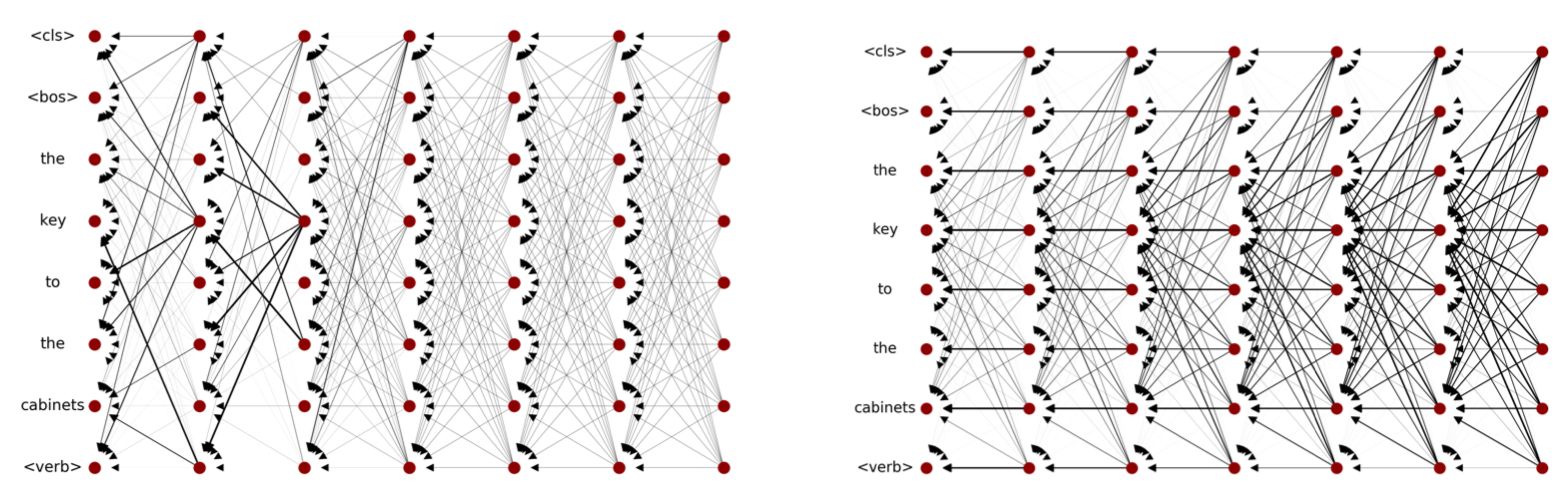
Below, we see a visualization of this issue, where for a BERT-style encoder in a subject-verb agreement classification model the attention between the classification token (<CLS> token, which is ultimately used to make the subject-verb classification) and all other input tokens is plotted. The attention signal disappears as you move deeper down the stack of self-attention layers, where for layers deeper than layer 3 the attention map can't be meaningfully interpreted at all.
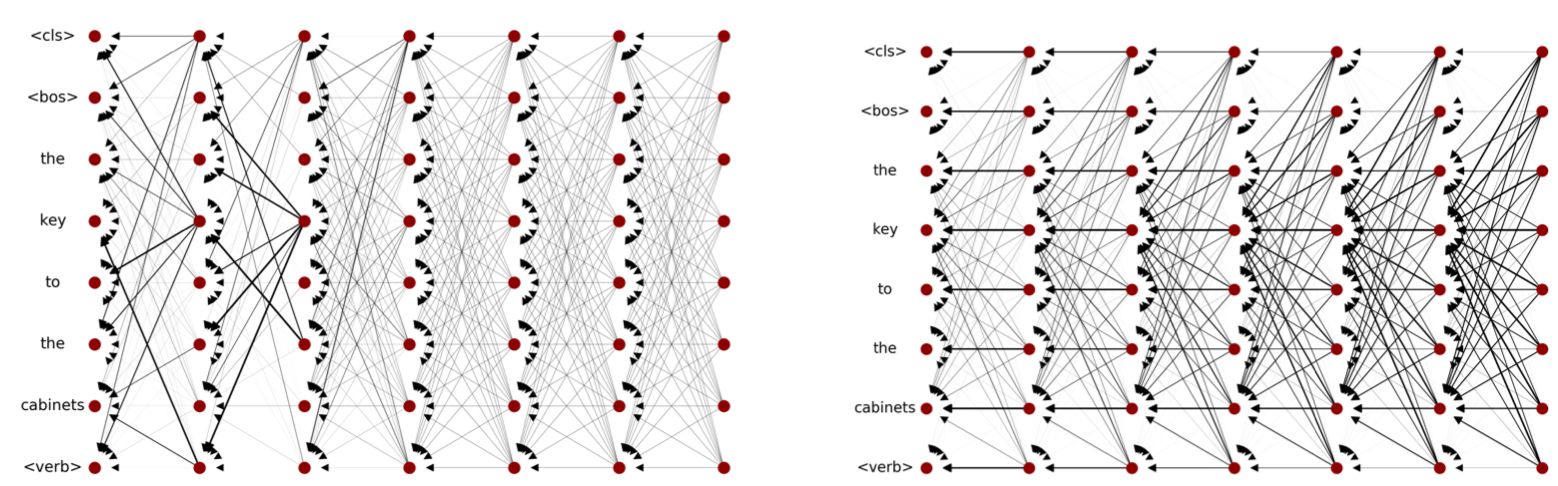
This is where attention rollout comes in. Attention rollout is a method introduced by Abnar et al. [1] that aims to remedy this issue of attention explainability for later layers in self-attention encoders. Notice in the figure below how the attention signal propagates through the entire network, rather than only the first few layers.
The algorithm for attention rollout is surprisingly simple. It's a recursive algorithm, in which we start at the beginning of the network and progressively take the dot product of each layers attention map.
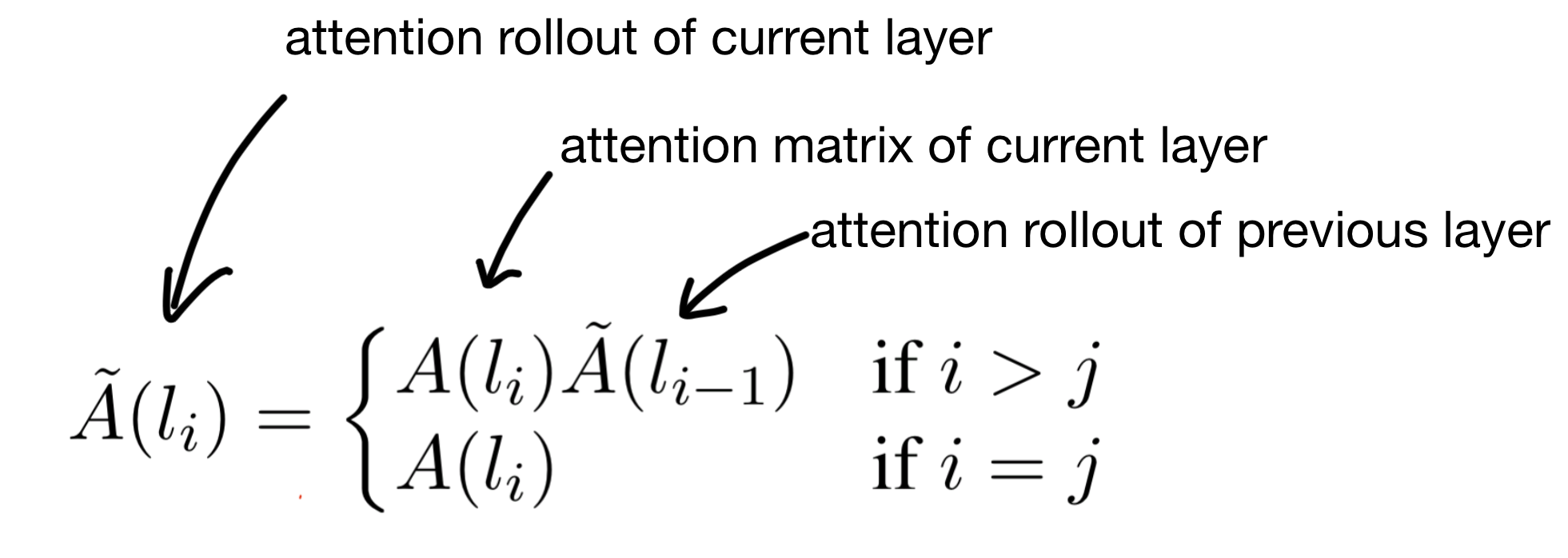
The base case for the recursion is to simply take the attention map for the first layer (in this case where j = 0). Then for each layer we multiply the previous layers result by the current layers attention map.
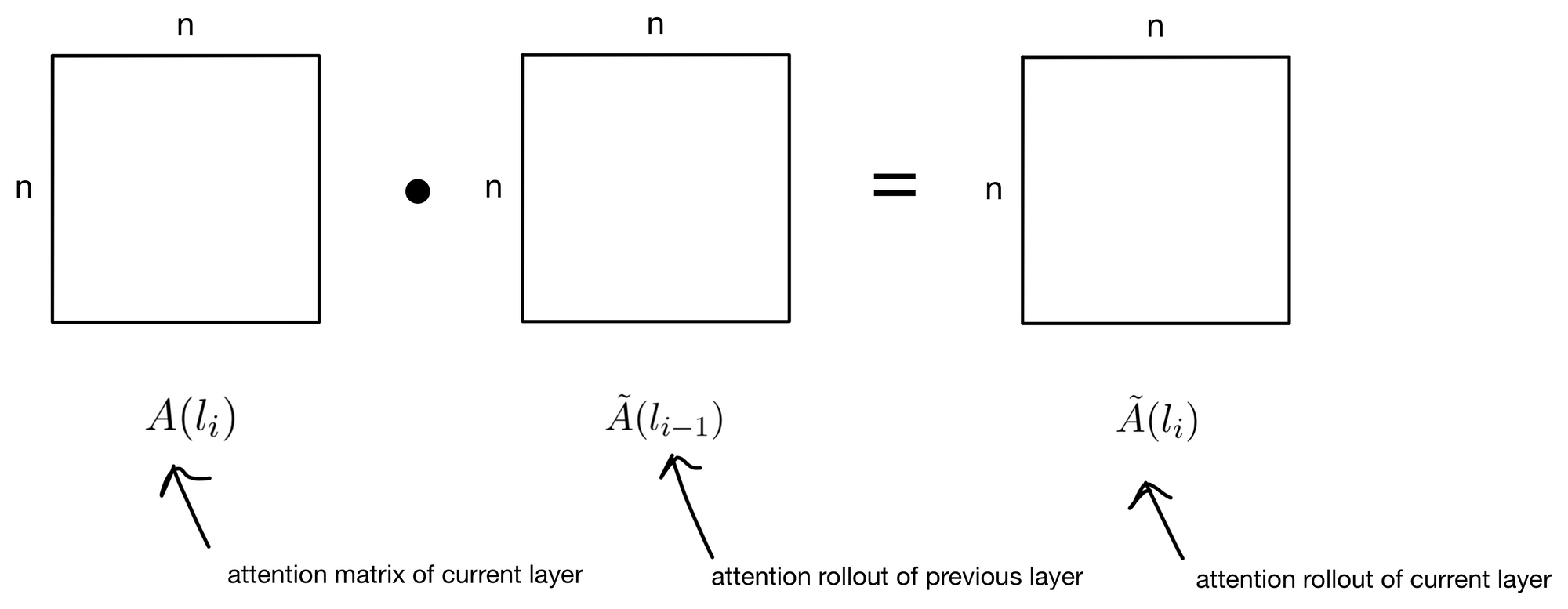
That's it! This trick allows attention to be more meaningfully visualized and interpreted for deeper layers in a transformer.
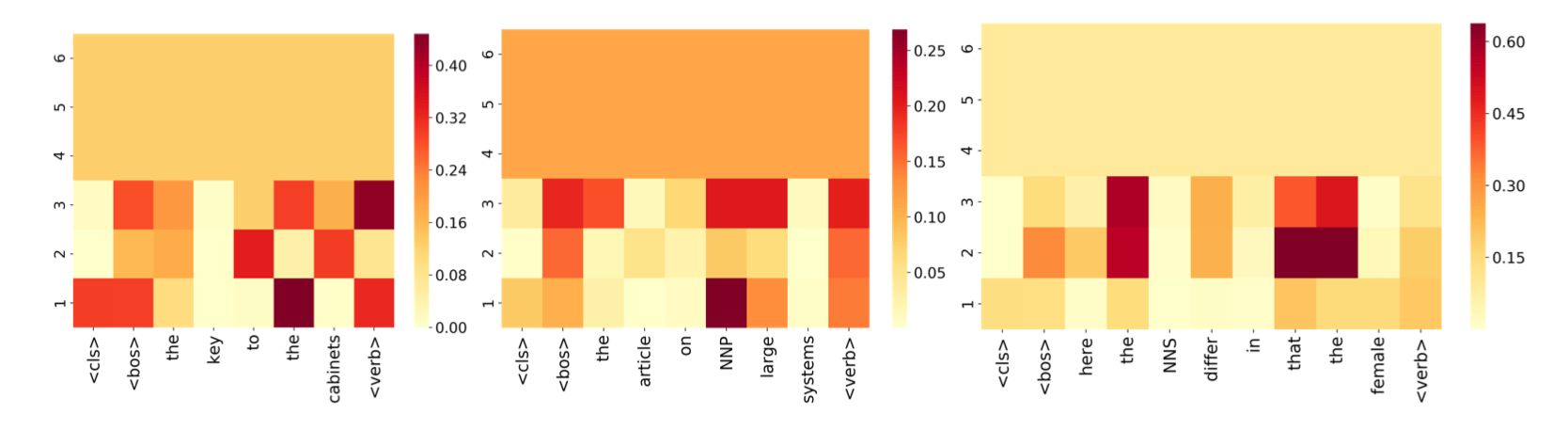
Take this example below, where attention rollout is applied to the same set of prompts shown in the beginning of the post.
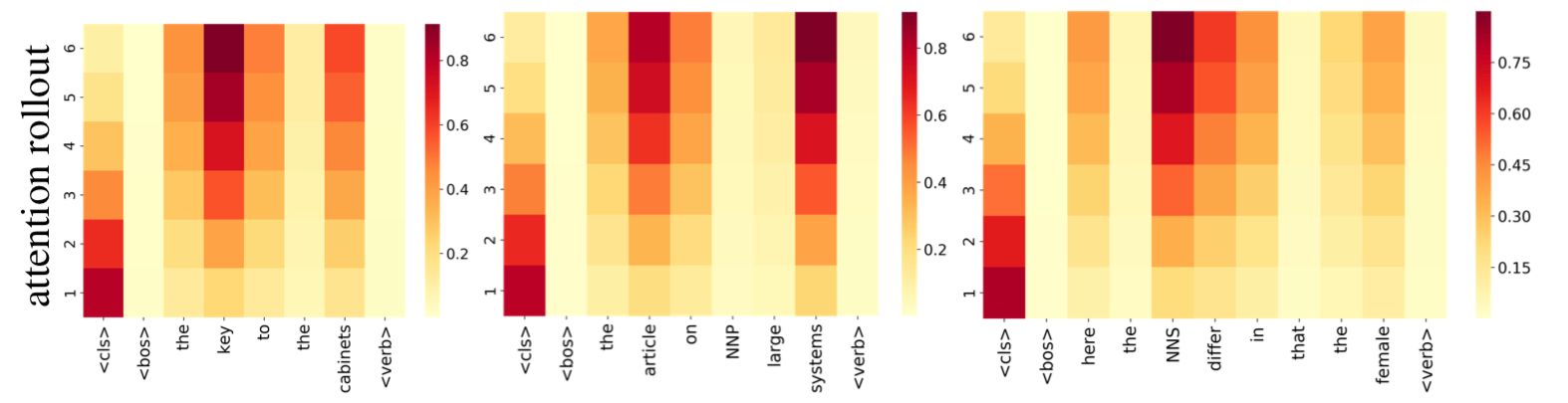
Clearly, the deeper layers of the network are keeping their signal to a greater degree than if we look at just the raw attention maps.
There you have it, attention rollout. Hope you enjoyed the post!
1. Abnar et al.: https://arxiv.org/abs/2005.00928